Введение архитектуры Zen 5 — это лишь часть истории. Настоящая революция от AMD заключена в мобильных процессорах серии Ryzen AI 300 (кодовое имя Strix Point). Это не просто «процессор с графикой», а сложная гетерогенная система на кристалле (SoC), объединяющая три ключевых архитектуры: Zen 5, RDNA 3.5 и XDNA 2. Это качественный скачок от обычного CPU со «встройкой» к специализированному вычислительному центру.
Три кита новой архитектуры: Разбираем компоненты
AMD Zen 5: Фундаментальная вычислительная мощность
Подробно архитектуру Zen 5 мы рассматривали в предыдущей статье Рассматриваем архитектуру процессоров AMD Zen 5. Напомню, что новейшая архитектура CPU-ядер предлагает следующие ключевые изменения: увеличенная ширина декодера (6 инструкций/такт), больше исполнительных блоков (ALU/AGU), нативная поддержка AVX-512.
Однако, rлючевая особенность в Strix Point в том, что впервые в истории AMD используется гибридная архитектура Big.LITTLE.
-
-
«Big»-ядра: Это полноценные высокопроизводительные ядра Zen 5.
-
«LITTLE»-ядра: Это Zen 5c-ядра. Это не урезанная архитектура, их IPC (производительность на такт) идентична полноценным Zen 5. Их отличие — оптимизация под плотность размещения на кристалле. Они немного медленнее в пиковой частоте, но гораздо более энергоэффективны и занимают меньше места. Само собой, их нельзя разгонять, но в своей базовой частоте они делают очень хорошую работу.
-
Цель использования такой комбинации в том, чтобы оптимальнее распределить нагрузку. Фоновые и легкие задачи выполняются на энергоэффективных Zen 5c, освобождая и экономя заряд батареи. Тяжелые нагрузки (игры, рендеринг) используют полную мощь Zen 5.
AMD RDNA 3.5: Эволюция интегрированной графики
RDNA 3.5 — это улучшенная версия графической архитектуры RDNA 3. Суффикс «.5» указывает на значительный рефайнмент, а не на новое поколение. Это не «обычное встроенное ядро» — это мощный iGPU, сопоставимый с дискретными картами начального уровня. AMD заявляет, что RDNA 3.5 блоки на 19-32% быстрее предыдущего поколения (производительность на ватт), что является большим скачком.
Компоновка блоков в iGPU выглядит следующим образом: как в обычном процессоре есть планировщик и блоки асинхронных вычислений — блок обсчета геометрии, который взаимодействует с группой шейдерных (текстурных) процессоров и пиксельным конвейером. Вычислительные блоки общаются с кэшем L1 и L2. Планировщик через командный процессор отвечает за загрузку исполнительных блоков и кэшей командами.
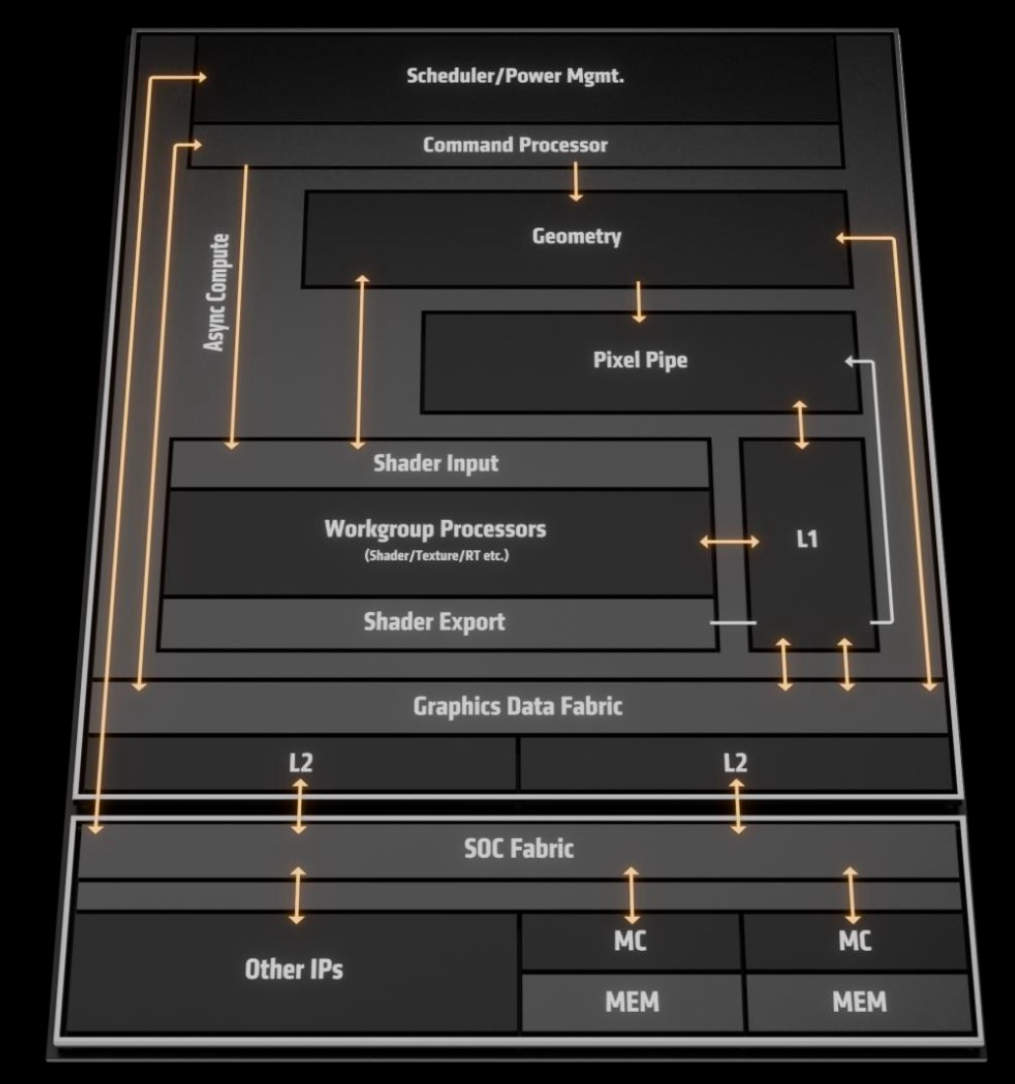
От конвейеров к Unified Shaders
Исторически в GPU были отдельные, фиксированные блоки («конвейеры») для разных задач: Pixel Pipelines, Vertex Pipelines, Texture Units. Современная архитектура отказалась от этого в пользу Unified Shader Architecture (единой шейдерной архитектуры).
Теперь нет отдельных аппаратных блоков для пиксельных или вертексных шейдеров. Вместо этого есть большой массив универсальных вычислительных ядер (Stream Processors / Shader Cores). Эти ядра могут выполнять любой тип шейдерного кода: вертексный, пиксельный, геометрический, вычислений (Compute). Какой код выполнять — решает планировщик (scheduler), который распределяет задачи по ядрам.
Таким образом, термин «Pixel Pipe» (пиксельный конвейер) в его классическом понимании устарел. Сегодня это не физический, а логический конвейер, путь, который данные проходят через различные стадии и блоки GPU для окончательного формирования пикселя.
Pixel Pipe в современном GPU
Это последовательность этапов, через которые проходит фрагмент (пиксель-кандидат) для рендера. Вот как это выглядит упрощенно:
-
Растеризация (Rasterization): Превращение треугольников (примитивов) в набор фрагментов (fragments). Фрагмент — это потенциальный пиксель с данными: координаты, глубина, цвет, текстурные координаты.
-
Текстурирование (Texture Fetch): Для каждого фрагмента нужно определить его цвет. Шейдерный процессор запрашивает данные из текстур. Этим занимаются Texture Units.
-
Исполнение пиксельного шейдера (Pixel Shader Execution): Универсальные шейдерные ядра выполняют код пиксельного шейдера для этого фрагмента. Код может использовать данные текстурирования, выполнять сложные математические расчеты для освещения и т.д.
-
Блендинг (Blending) / Смешивание: Обработанный фрагмент комбинируется с текущим цветом в буфере кадра (frame buffer) согласно настройкам прозрачности (alpha blending).
-
Запись в буфер кадра (Render Output): Финальный цвет пикселя записывается в память.
Конвейером (pipe) можно назвать весь этот маршрут, который должен обработать каждый из миллионов пикселей. Параллельно работают тысячи таких «логических конвейеров».
Shader Texture Workgroup Processors — сердце современного iGPU
Это уже не логика, а физическая аппаратная организация. В архитектурах AMD RDNA 2 и RDNA 3 основная строительная единица — это Workgroup Processor (WGP) или Dual Compute Unit (DCU).
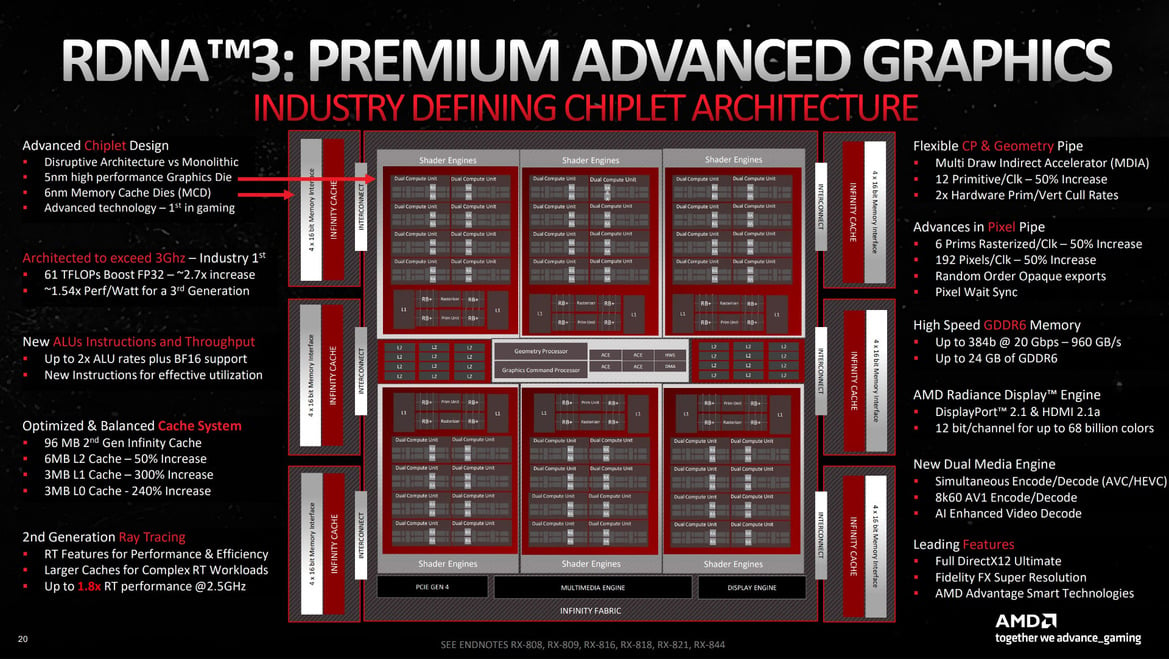
Давайте разберем его иерархически:
а) Весь iGPU (например, 12 CU)
Состоит из нескольких массивов Shader Engines. Каждый массив содержит несколько WGP.
б) Workgroup Processor (WGP) — Ключевой блок!
Один WGP — это, по сути, 2 независимых Compute Unit (CU), объединенных общим ресурсом, поэтому они и называются «рабочей группой». Это фундаментальный блок планирования и выполнения задач. WGP получает от планировщика «рабочей группы» пакет потоков (threads), которые нужно выполнить. Эти потоки могут быть пикселями, вершинами или элементами вычислений.
в) Compute Unit (CU) — внутри WGP
Это и есть те самые «шейдерные ядра» или «поточные процессоры». Один CU в RDNA содержит:
-
2 SIMD-32 векторных блока: Каждый SIMD-32 может выполнять одну инструкцию над 32 потоками (пикселями, вершинами) одновременно за такт. Это основа массового параллелизма.
-
1 скалярный блок (Scalar Unit): Выполняет одну инструкцию для всей волны (wavefront) из 32 потоков. Обрабатывает инструкции потока управления (if/else, loops), константы — то, что одинаково для всех 32 пикселей.
-
Регистровый файл (Register File): Огромная и очень быстрая память для хранения данных всех активных потоков в этом CU.
-
Кэш L0 для инструкций и данных: Сверхбыстрая локальная память для кода и данных, с которым CU работает прямо сейчас.
-
Текстурные блоки (Texture Units): Каждый CU имеет собственные 4 текстурных блока (TMU — Texture Mapping Units), которые вычисляют цвет пикселей.
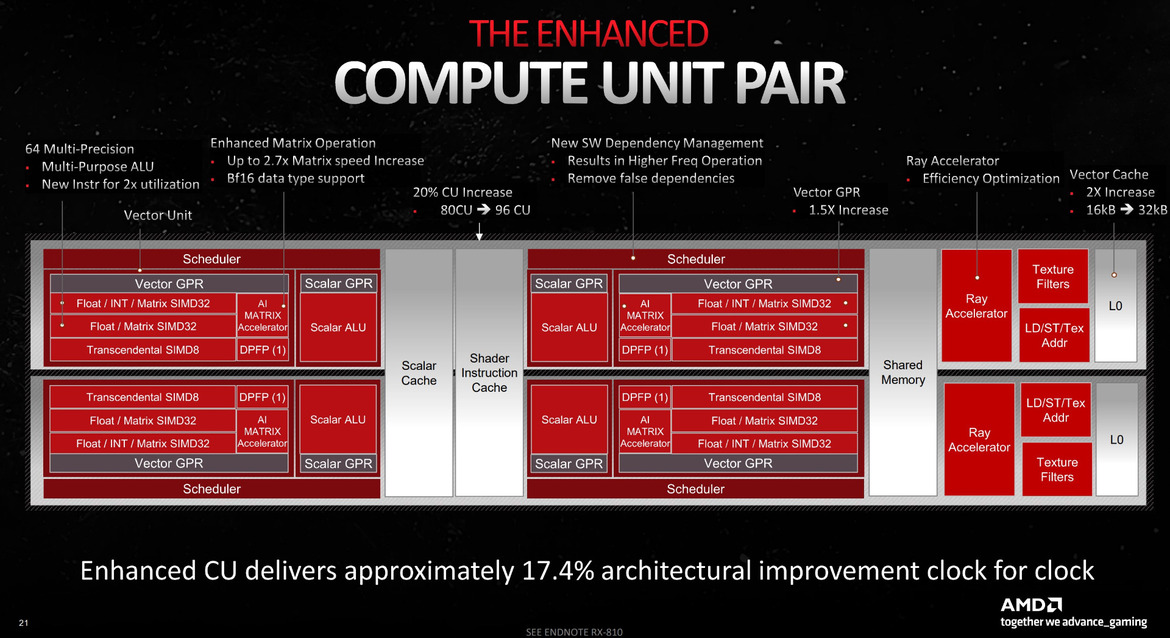
Как это работает вместе на примере текстурирования:
-
Пиксельный шейдер, выполняющийся на одном из SIMD-32 блоков CU, встречает инструкцию
textureSample. -
Эта инструкция отправляется не на выполнение в ALU, а в один из 4-х текстурных блоков (TMU), прикрепленных к этому же CU.
-
Текстурный блок, получив координаты из 32 потоков одной волны (wavefronts/warps), выполняет параллельную выборку из текстурного кэша.
-
Текстурный блок возвращает результат (цвет текстуры для каждого из 32 пикселей) обратно в шейдерные ядра, которые продолжают вычисления.
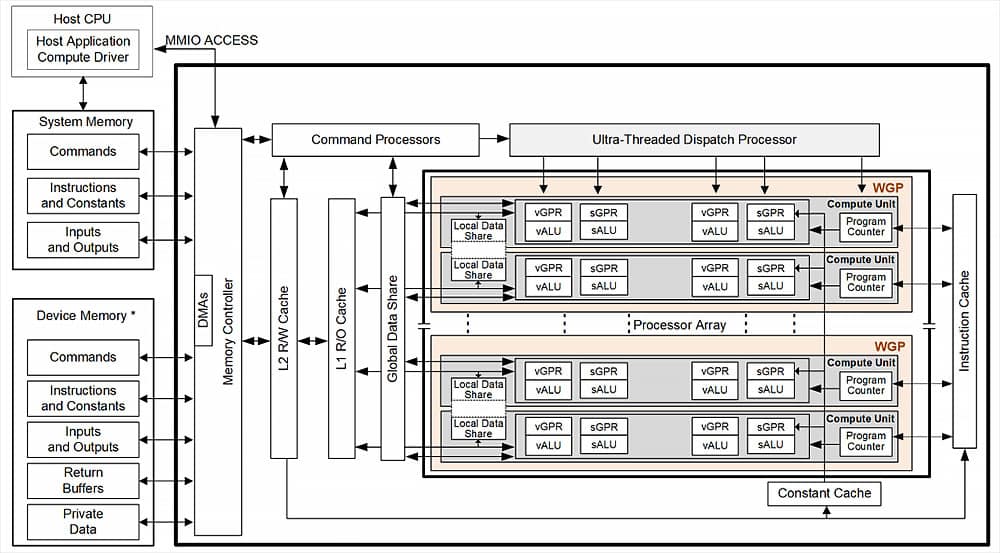
Преимущество такой архитектуры:
-
Минимальные задержки: Текстурные блоки физически расположены прямо рядом с шейдерными ядрами, которые их используют.
-
Сверхбыстрый доступ: У каждого CU есть свой доступ к общему кэшу текстур L1 и дальше к L2.
-
Баланс: На каждые 64 потоковых процессора (2 SIMD-32 * 32 потока) приходится 4 текстурных блока. Это тщательно просчитанное соотношение, чтобы шейдерные ядра не простаивали в ожидании данных из текстур и не конкурировали в ожидании ресурсов на текстурирование.
Ключевые особенности и отличия RNDA 3.5
-
-
Вычислительные блоки (WGP): Количество Compute Units (CU) было удвоено по сравнению с предыдущим поколением (RDNA 3 в Phoenix). В топовой модели 16 CU (1024 потоковых процессора). Это уровень дискретной карты Radeon RX 7600M XT.
-
Архитектурные улучшения: Были переработаны геометрические конвейеры и кэши второго уровня, что улучшило эффективность на такт.
-
Память: Использует высокоскоростную оперативную память (LPDDR5X) в качестве видеопамяти, что обеспечивает огромную пропускную способность.
-
Технологии: Поддержка всех современных API (DirectX 12 Ultimate, Vulkan), аппаратное ускорение трассировки лучей (Raytracing), AI-ускорение (матричные инструкции WMMA).
-
Традиционная «встройка» — это 2-4 CU, предназначенные для вывода изображения и нетребовательных игр. RDNA 3.5 в Ryzen AI — это высокопроизводительный игровой и дизайн движок, способный обеспечить комфортный гейминг в Full HD и работу с профессиональными приложениями.
AMD XDNA 2: Специализированный AI-движок (NPU)
Neural Processing Unit (NPU) — это специализированный процессор, созданный исключительно для выполнения задач искусственного интеллекта и машинного обучения.
Ключевые особенности:
-
-
Производительность: 50 TOPS (триллионов операций в секунду) только на NPU. Это более чем в 3 раза превышает показатель первого поколения XDNA (ZEN 4 Phoenix) и превышает требование Microsoft в 40 TOPS для Copilot+ PC. AMD заявляет, что XDNA 2 в 5 раз быстрее при в 2 раза меньшем потреблении энергии по сравнению с семейством Ryzen 7040.
-
Энергоэффективность: Выполнение AI-задач (обработка изображений с камеры, шумоподавление, автоматическое фреймирование, Stable Diffusion) на NPU потребляет на порядки меньше энергии, чем при использовании классических CPU или GPU. Это критически важно для автономности ноутбуков.
-
Специализация: Аппаратно оптимизирован для матричных умножений и работы с INT8/INT4/BF16 данными, что является стандартом для нейросетей.
-
Попытка запустить AI-нагрузку на GPU возможна, но крайне неэффективна. Это как использовать грузовик для перевозки одного пассажира. XDNA 2 — это «спортивный автомобиль», построенный для одной конкретной, но невероятно важной цели.
Сравнение с поколением Zen 4
Сравним поколения графики на примере Ryzen 7040HS «Phoenix» vs Ryzen AI 9 HX 370 «Strix Point».
| Компонент | Поколение Zen 4 (Phoenix, Hawk Point) | Поколение Zen 5 (Strix Point) | Количественное и качественное отличие |
|---|---|---|---|
| CPU Архитектура | Monolithic Die с одним типом ядер: • 8 ядер Zen 4 |
Monolithic Die с гибридной архитектурой: • До 4 ядер Zen 5 • До 8 ядер Zen 5c |
• +50% ядер (12 vs 8) • Гибридность для эффективности • ~16% прирост IPC (Zen 5 vs Zen 4) |
| GPU Архитектура | RDNA 3 • До 12 Compute Units (CU) • 768 потоковых процессоров |
RDNA 3.5 • До 16 Compute Units (CU) • 1024 потоковых процессора |
• +33% вычислительных блоков • Архитектурные улучшения IPC • Качественный скачок в игровой производительности |
| NPU Архитектура | XDNA 1 (Ryzen AI) • До ~10-16 TOPS |
XDNA 2 (Ryzen AI) • 50 TOPS |
• Рост производительности в 3-5 раз • Соответствие стандарту Copilot+ PC |
| Техпроцесс | TSMC N4 | TSMC N4P | Повышенная плотность транзисторов и энергоэффективность |
Эволюция от iGPU к гетерогенным вычислениям
Раньше «процессор с графикой» означал, что к CPU-ядру добавили скромный графический блок. Ryzen AI 300 Series на базе Zen 5, RDNA 3.5 и XDNA 2 — это нечто фундаментально иное.
Это сбалансированная вычислительная платформа, где:
-
Zen 5 отвечает за традиционную многопоточную и однопоточную производительность.
-
RDNA 3.5 представляет собой мощнейшую в отрасли интегрированную графику, стирающую грань между iGPU и dGPU начального уровня.
-
XDNA 2 — это специализированный, невероятно эффективный AI-акселератор, который определяет будущее взаимодействия с ПК.
Объединение этих трех архитектур на одном кристалле по передовому техпроцессу TSMC N4P создает APU беспрецедентной мощности и эффективности, задавая новый стандарт для мобильных вычислений и открывая эру истинных AI-PC.
 [Посещений: 100, из них сегодня: 1]
[Посещений: 100, из них сегодня: 1]