Zen 5 — новейшая и самая прогрессивная архитектура процессоров от AMD, представленная в 2024 году. Intel на тот момент нечем было ответить и только в 2025 году они приготовили аналог, но сейчас не о нем.
В линейку процессоров на Zen 5 входят десктопные, мобильные и серверные процессоры:
1. Десктопные процессоры (Ryzen 9000 Series)
Стандартные модели Ryzen 9000 (Granite Ridge)
Игровые модели с 3D V-Cache (Ryzen 9000X3D)
2. Мобильные процессоры (Ryzen AI 300 Series и Fire Range)
Ryzen AI 300 Series (Strix Point)
Дополнительные мобильные Zen 5 процессоры (2025)
3. Серверные и корпоративные процессоры (EPYC Series)
EPYC 9005 Series («Turin»)
EPYC 4005 Series («Grado»)
4. Процессоры для рабочих станций (Threadripper)
Ryzen Threadripper PRO 9000 WX-Series
Но в чем принципиальные отличия этих процессоров от прежней архитектуры Zen 4? Разберемся в этой статье.
Анонс микроархитектуры AMD Zen 5 ознаменовал собой не просто итеративное обновление, а один из самых значительных скачков в эффективности IPC (Instructions Per Clock) со времён выхода оригинального Zen. Кодовое название ядра — «Сарамчи» (Saramchi), что подчёркивает его преемственность по отношению к Zen 4 («Рафаэль») и в то же время говорит о кардинальных внутренних изменениях.
Если Zen 4 был во многом «шлифовкой» и адаптацией Zen 3 под новый техпроцесс TSMC 5 нм, то Zen 5 — это глубокая переработка большинства ключевых компонентов ядра. Заявленный прирост IPC до 16% в специфичных нагрузках — результат многочисленных улучшений в фронтенде и бэкенде процессора.
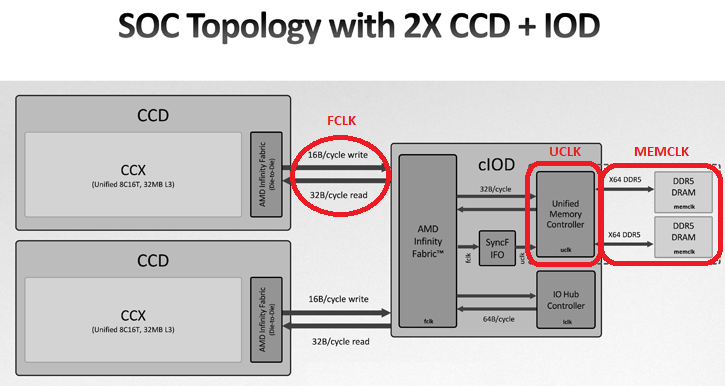
Произошел переход на чиплетный дизайн кристаллов процессоров: новый подход называется CCD (Core Complex Die), что означает сложную компоновку, где на одной подложке расположено несколько кристаллов (die), соединенных между собой.
Посмотрим на состав Granite Ridge. На фото видно, что он состоит из 2 кристаллов:
Кристаллы соединены через шину Infinity Fabric over Package (IFoP), контроллеры которой есть в обоих чипах. Это проприетарная разработка AMD. IFoP обеспечивает высокую пропускную способность чтения и записи между кристаллами при определенной тактовой частоте (FCLK), которую можно синхронизировать с частотой памяти (MCLK) для оптимальной производительности и минимальной задержки.
Вообще использование шины между кристаллами влечет за собой задержку по сравнению с внедрением всех блоков в один кристалл. Но на данном этапе это становится невозможным из-за слишком большого количества блоков в ядрах. Именно поэтому поддержание точного соотношения между FCLK (тактовой частотой Infinity Fabric) и MEMCLK (тактовой частотой памяти), например, FCLK 2200 с DDR5-6600, что составляет 1:3, обеспечивает меньшую задержку по сравнению с FCLK 2200 с DDR5-6400.
В блоке cIOD также находится унифицированный контроллер памяти (UMC). Этот блок отвечает за обработку временных аспектов, таких как тайминги памяти и управление запросами доступа от процессора. Он работает на частоте UCLK, которая может быть равна MEMCLK (UCLK = MEMCLK) или работать на половине её частоты (UCLK = MEMCLK / 2).
Важно отметить, что при UCLK, равной MEMCLK, максимальная стабильная частота памяти обычно ограничена 6400 МТ/с, и лишь в некоторых случаях достигает 6600 МТ/с. При частоте UCLK, равной половине частоты MEMCLK, теоретически возможно достижение скорости 8000 МТ/с и более. Однако в этом режиме важно максимально повысить частоту памяти, чтобы компенсировать более медленную работу контроллера.
Физические схемы FHY используются не только для связи между CCD и cIOD. Эти схемы также необходимы для подключения микросхем памяти, находящихся на материнской плате, к UMC. Они обеспечивают электрическую связь между компонентами, и именно здесь важны настройки импеданса и согласования. Эти факторы влияют на целостность сигнала и стабильность системы, особенно при использовании более высоких частот памяти.
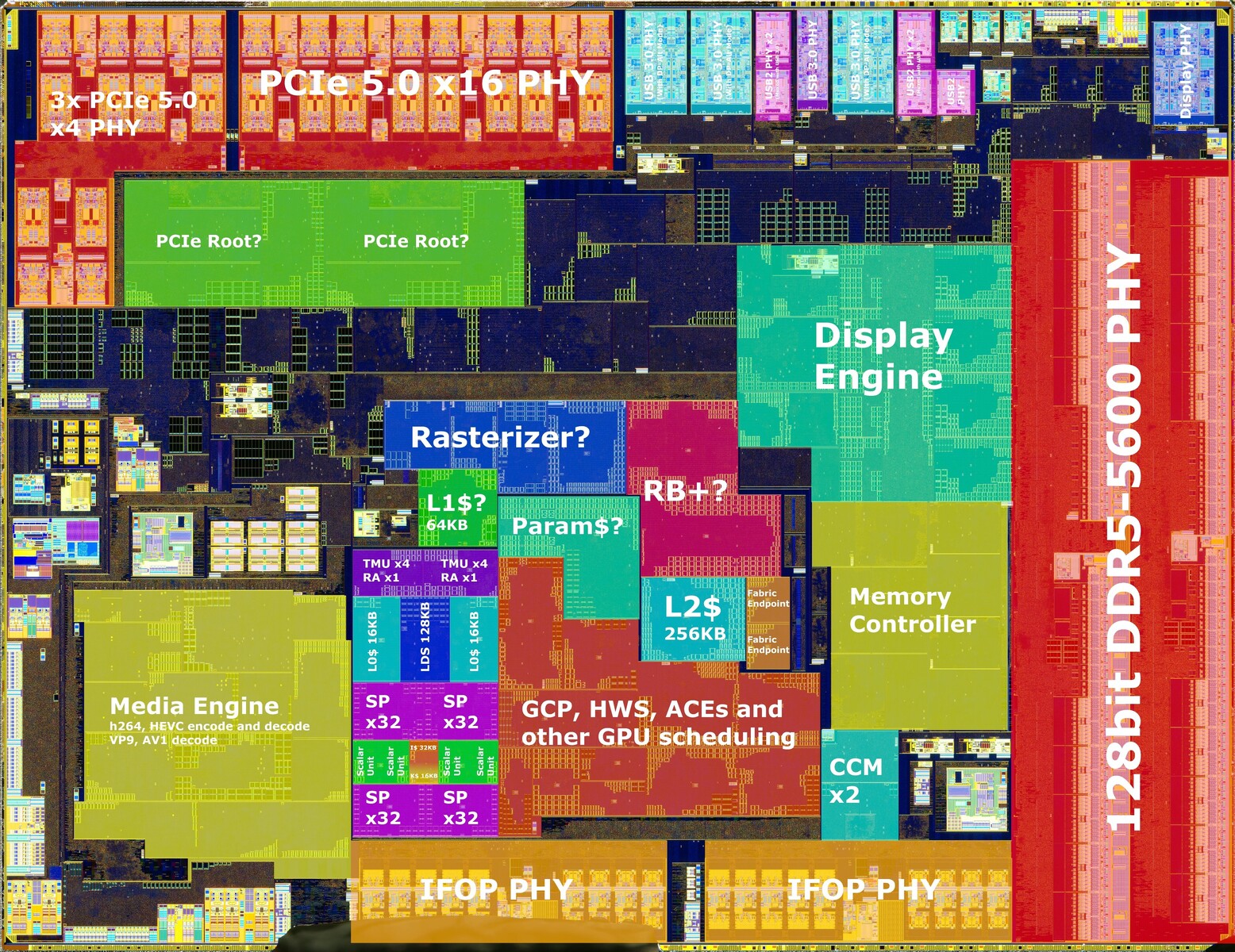
Здесь нет ничего нового: чип заимствован у Zen 4 «Raphael». Он построен на технологическом процессе TSMC N6 (6 нм). Почти треть площади кристалла занимает встроенный графический процессор (iGPU) и связанные с ним компоненты, такие как модуль ускорения мультимедиа и модуль дисплея. iGPU основан на графической архитектуре RDNA 2 и имеет всего один процессор рабочей группы (WGP) для двух вычислительных блоков (CU) или 128 потоковых процессоров.
Другими ключевыми компонентами cIOD являются 28-канальный интерфейс PCIe Gen 5, два порта IFoP для CCD, довольно большой блок ввода-вывода, состоящий из USB 3.x и устаревших интерфейсов, а также важнейший контроллер памяти DDR5 с двухканальным (четыре подканала) интерфейсом памяти.
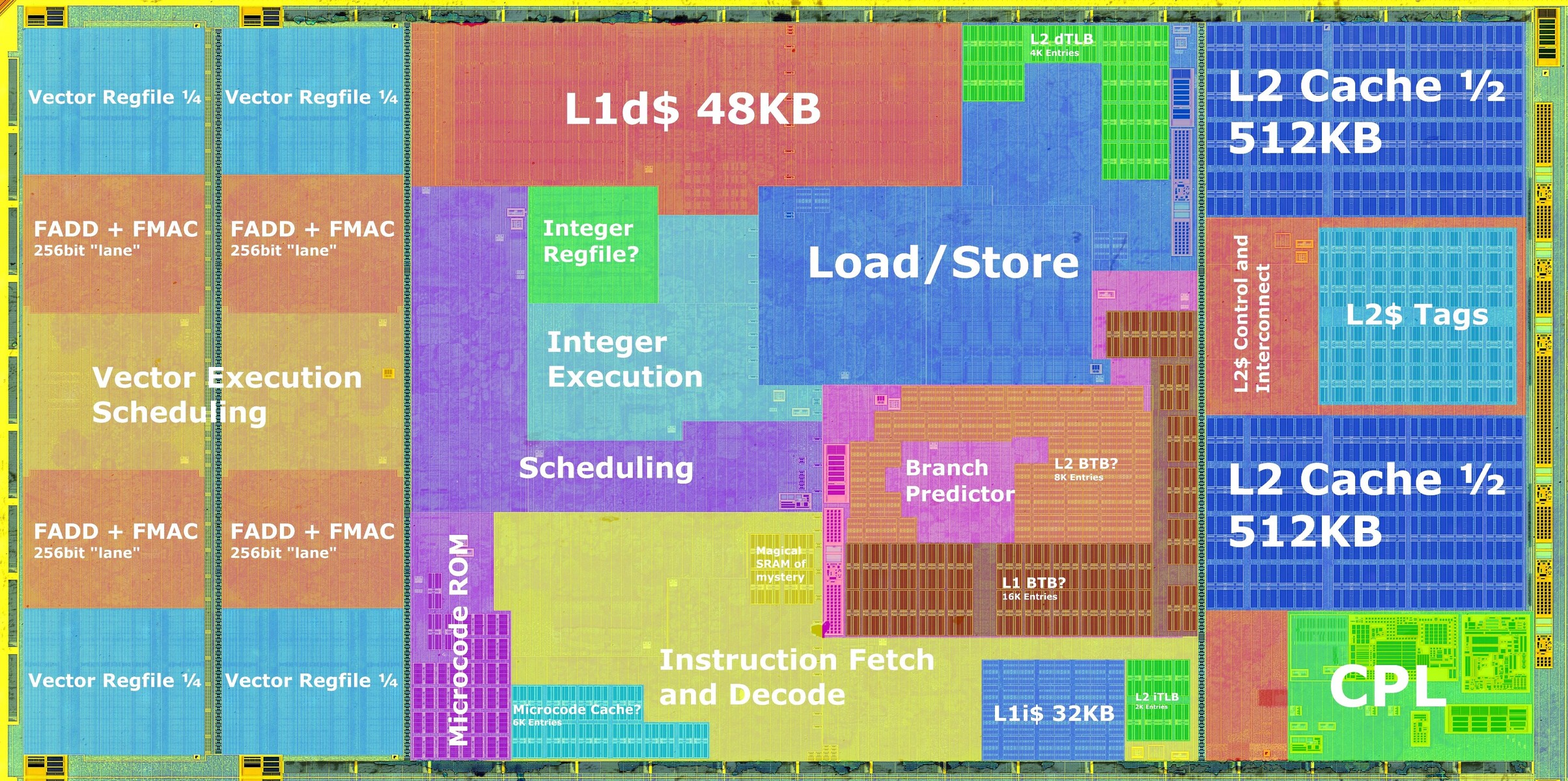
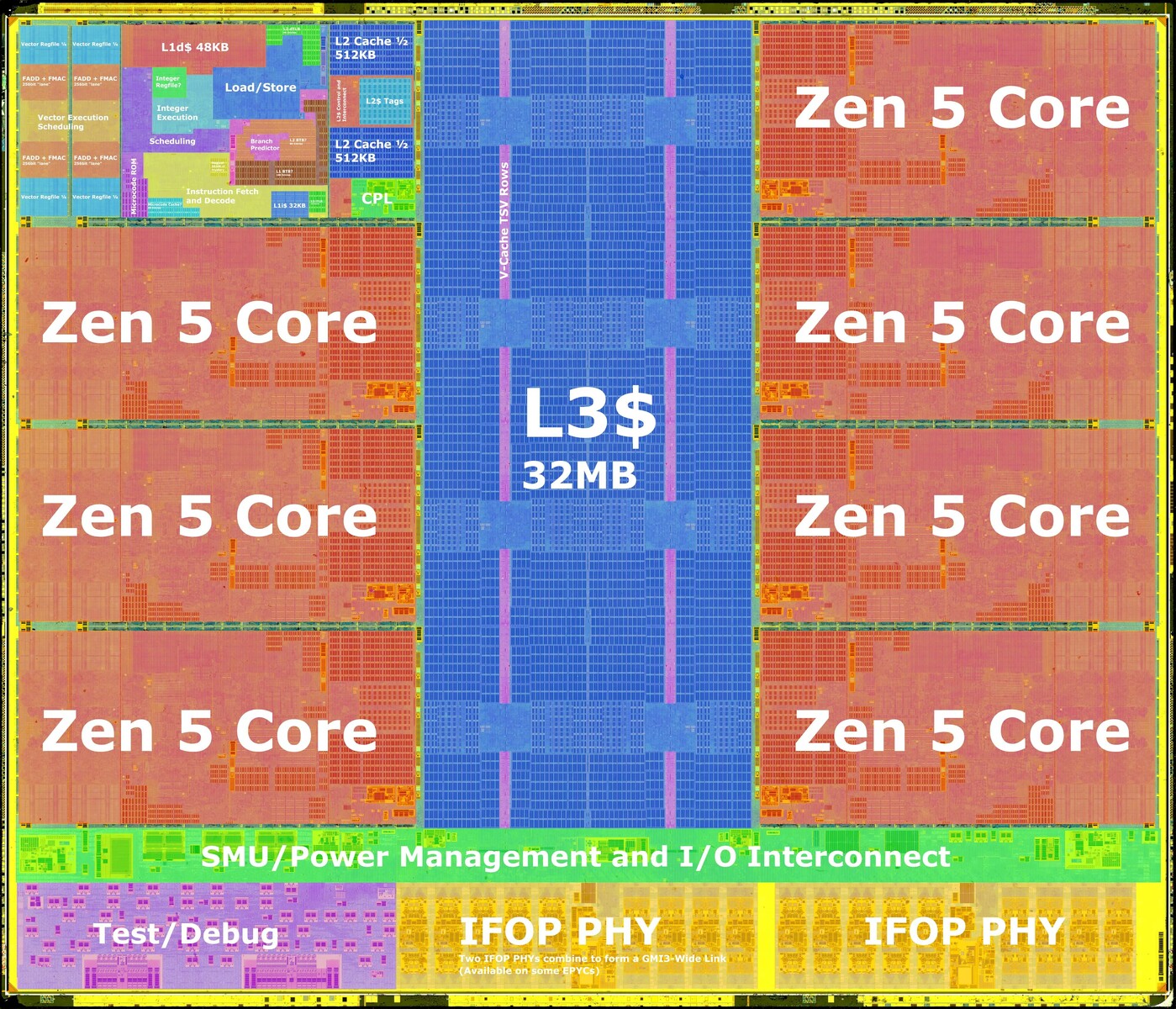
Ядро отвечает непосредственно за вычисления. Каждое ядро Zen 5 физически больше ядра Zen 4 (созданного по техпроцессу TSMC N5) благодаря внутренней 512-битной шине данных с плавающей запятой. Векторный движок ядра вынесен на самый край ядра. Блоки вычисления c плавающей запятой (FPU) обычно являются самыми горячими компонентами ядра процессора, поэтому это вполне логично.
Vector execution scheduling — это специализированный блок в архитектуре процессора, который отвечает за организацию и управление выполнением векторных инструкций. Векторные инструкции — это команды, которые позволяют процессору выполнять одну и ту же операцию сразу над множеством данных (вектором), а не над одним элементом. Такой подход реализует параллелизм на уровне данных (SIMD — Single Instruction, Multiple Data) и значительно ускоряет обработку больших массивов данных, что особенно важно для научных расчетов, машинного обучения, обработки изображений и других задач с интенсивной обработкой данных.
Vector regfile (или vector register file, векторный регистровый файл) — это специализированный набор регистров в процессоре, предназначенный для хранения целых векторов данных, а не отдельных скалярных значений. Каждый такой регистр может содержать сразу несколько элементов (например, 8, 16, 32 или даже 64 числа с плавающей точкой или целых числа), что позволяет выполнять операции над всеми этими элементами одновременно.
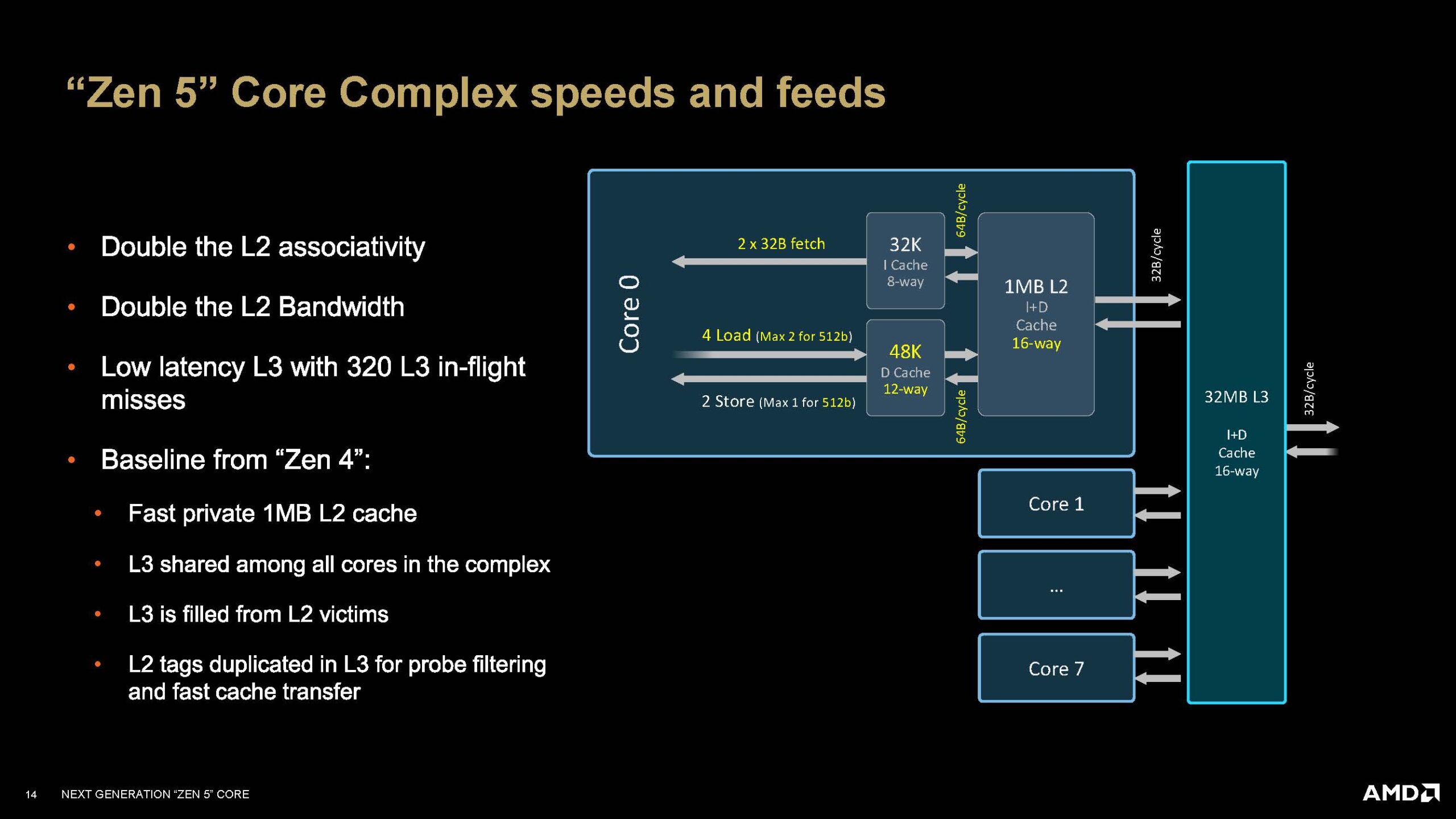
Кэш второго уровня объёмом 1 МБ (2 блока по 512 КБ) также находится с краю компоновки ядра. AMD удвоила пропускную способность и ассоциативность кэша L2 по сравнению с ядром Zen 4. Ассоциативность кэша процессора — это характеристика, определяющая, в скольких различных местах (строках) кэша может быть размещён один и тот же блок данных из оперативной памяти. Чем выше ассоциативность, тем меньше вероятность конфликтов, но выше сложность и задержки при поиске данных. В современных процессорах чаще всего используется многоканальная ассоциативность (например, 4-, 8-, 16-канальная), как компромисс между скоростью и эффективностью использования кэша.
Важное место в обращении к L2 кэшу занимают блоки L2 BTB и L2 TLB. BTB (Branch Target Buffer) хранит адреса целей переходов (ветвлений) в программе, чтобы процессор мог заранее знать, куда пойдет выполнение после условного или безусловного перехода. Это помогает уменьшить задержки, связанные с ветвлениями, и повысить эффективность конвейера процессора. TLB (Translation Lookaside Buffer) — это специализированный кэш, который хранит недавно использованные преобразования виртуальных адресов в физические. Поскольку процессоры используют виртуальную память, при обращении к памяти сначала нужно преобразовать виртуальный адрес в физический. Это преобразование происходит через таблицы страниц, но обращение к ним медленное. TLB — это быстрый кэш этих преобразований, который значительно ускоряет доступ к памяти. Если нужная запись есть в TLB (TLB hit), процессор быстро получает физический адрес; если нет (TLB miss), происходит более медленное обращение к таблицам страниц.
Центральная область ядра Zen 5 содержит 32 КБ кэша первого уровня для инструкций (L1I), 48 КБ кэша первого уровня для данных (L1D), блок выполнения целочисленных операций (Integer Execution Engine) и важнейшую составляющую процессора с блоком выборки и декодирования инструкций (Instruction Fetch & Decode), блоком предсказания ветвлений (Branch Prediction Unit), кэшем микроопераций (microop cache) и планировщиком. От блока предсказания ветвлений (Branch predictor) и загрузки кэшей очень сильно зависит эффектность работы вычислительных блоков и всего конвейера вычисления в целом.
Кэш третьего уровня L3 объёмом 32 МБ — общий для всех ядер на одном кристалле CCD, которых может быть до 8 шт.
Кэш L3 на ядре имеет ряды TSV (сквозных кремниевых переходных отверстий), которые служат резервом для трёхмерного V-кэша. 64 МБ кэш-памяти L3D (кристалл кэша L3) подключается к кольцевой шине CCD посредством этих TSV, обеспечивая смежный доступ к 64 МБ 3D V-кэша и 32 МБ встроенного кэша L3.
Теперь, когда мы разобрались из каких блоково состоит процессор поколения Zen 5, можно сравнить, в чем заключаются улучшения архитектуры по сравнению с предыдущим поколением.
Фронтенд отвечает за бесперебойную подачу инструкций в конвейер. В Zen 5 он был значительно переработан.
Удвоенная пропускная способность декодера команд: Это одно из важнейших изменений. Ядро Zen 5 теперь может декодировать до 6 инструкций за такт (по сравнению с 4 у Zen 4). Это означает, что он быстрее заполняет буферы последующих стадий более мелкими операциями (µops), что критично для обработки сложных, разветвлённых workloads.
Усовершенствованный предсказатель переходов (Branch Predictor): AMD заявляет о существенном уменьшении количества ошибок предсказания (mispredictions). Был улучшен алгоритм предсказания косвенных переходов (indirect branches), которые традиционно являются сложными для предсказания. Меньше ошибок — меньше сбросов конвейера и холостых тактов процессора.
Увеличенный и переработанный кэш L1I (Instruction Cache): Размер остался прежним (32 КБ), но его ассоциативность была повышена, а латентность уменьшена. Это снижает вероятность промахов и ускоряет доступ к критически важным инструкциям.
Увеличенный буфер микрокода (µOP Cache): Теперь он может хранить до 10 тыс. операций (против 6.75 тыс. в Zen 4). Когда процессор сталкивается с сложной инструкцией (например, из набора AVX-512), он разбивается на более простые µops и помещается в этот кэш. Его увеличение напрямую улучшает производительность при работе с векторными инструкциями.
Здесь происходят непосредственные вычисления. Zen 5 получил серьёзные апгрейды как для целочисленных, так и для векторных операций.
Увеличение количества исполнительных блоков (ALU/AGU):
Целочисленные исполнительные блоки (Integer Execution Units): Количество АЛУ (ALU, арифметико-логическое устройство) и АГУ (AGU) было увеличено. Zen 5 теперь имеет шесть АЛУ (два из которых могут выполнять операции сдвига и умножения) и три АГУ (для расчёта адресов памяти). В Zen 4 их было 4+2 соответственно. Это напрямую повышает пропускную способность в integer-нагрузках.
Векторные/плавающие исполнительные блоки (Floating-Point/Vector Units): Математический блок был серьёзно усилен для работы с AVX-512. В Zen 4 для выполнения 512-битных инструкций они разбивались на два 256-битных микрокода. В Zen 5 реализована нативная поддержка AVX-512 с полноразмерными 512-битными исполнительными конвейерами. Это означает, что теперь одна 512-битная инструкция может быть обработана за один такт, что радикально повышает производительность в научных расчётах, задачах ИИ и шифрования.
Увеличенные окна планирования (Scheduler Windows): Чтобы кормить возросшее количество исполнительных блоков, необходимо большее «окно», где инструкции ожидают своей очереди на выполнение. Размер этих буферов (Integer Scheduler, FP Scheduler) был существенно увеличен, что позволяет процессору лучше находить параллельно исполняемые инструкции (выполнять вне порядка — Out-of-Order execution).
Улучшенный блок загрузки/сохранения (Load/Store Unit):
Пропускная способность: Количество операций загрузки (load) и сохранения (store) за такт было увеличено.
Буферы (Buffers): Размер буфера переупорядочивания памяти (MOB) и буфера сохранения (Store Buffer) был увеличен, что улучшает производительность в memory-bound задачах и снижает простои при работе с кэшем и оперативной памятью.
Кэш L2: Сохранил свой размер 1 МБ на ядро, но, по заявлениям AMD, его пропускная способность была существенно повышена, а также улучшена ассоциативность для улучшения загруженности кэша и меньших его сбросов.
Кэш L3: В десктопных процессорах серии Ryzen 9000 («Granite Ridge») используется тот же дизайн CCD (Core Complex Die) на 8 ядер с общим кэшем L3 объемом 32 МБ, что и в Zen 4. Ключевые улучшения касаются пропускной способности и снижения задержек доступа к нему.
| Характеристика | AMD Zen 5 (Saramchi) | AMD Zen 4 (Raphael) | Что это значит |
|---|---|---|---|
| Декодер команд | 6 инструкций/такт | 4 инструкции/такт | Лучшая обработка сложного кода, который декодируется в микрокоманды |
| Целочисленные АЛУ (ALU) | 6 (вкл. 2 для mul/shift) | 4 (вкл. 1 для mul/shift) | Выше производительность в integer вычислениях |
| АГУ (AGU) | 3 | 2 | Больше операций с памятью за такт |
| Векторные блоки (AVX-512) | Нативные 512-бит (1 такт) | 2×256-бит (2 такта) | 2-х кратное ускорение AVX-512 в векторных вычислениях |
| Кэш µOP | ~10 000 операций | ~6 750 операций | Лучшая эффективность сложных инструкций |
| Предсказатель переходов | Улучшенный алгоритм | Алгоритм Zen 4 | Меньше ошибок, выше эффективность |
| Техпроцесс | TSMC 4nm/3nm (Optimus) | TSMC 5nm (N5/N4) | Более высокая плотность и энергоэффективность |
Ни для кого не секрет, что у Zen 4 выход годных кристаллов был не таким уж и высоким и было достаточно много брака, а при попытках разгона процессоры часто выходили из строя из-за большого разброса по выдерживаемым параметрам напряжения. Что изменилось?
Переход на более тонкие нормы производства позволяет разместить больше транзисторов на той же площади (увеличивая сложность ядра) или снизить энергопотребление и тепловыделение при сопоставимой производительности.
Сравнение кристаллов Zen 4 и Zen 5 показывает гениальную и прагматичную стратегию AMD:
Радикальное обновление ядра (CCD): Инженеры AMD не стали жадничать и значительно увеличили размер и сложность ядра Zen 5, переведя его на более совершенные техпроцессы (N4P/N3E). Это дало рекордный прирост IPC и новые возможности вроде AVX-512.
Консервативность и экономия на платформе (IOD): Для десктопного сегмента AMD использовала проверенный и отлаженный IOD от Zen 4. Это позволило:
Таким образом, AMD удалось совместить в Zen 5 революцию в архитектуре ядра с эволюцией в дизайне чиплетов и платформы, что является образцом эффективного инженерного проектирования.
Новый техпроцесс N4P от TSMC — это ключевая технология для первых процессоров AMD на архитектуре Zen 5 (например, десктопных Ryzen 9000). Это не просто «4 нм», а целенаправленная оптимизация существующего процесса, оказывающая прямое влияние на характеристики транзисторов и, как следствие, на производительность и энергоэффективность чипов.
N4P является частью TSMC’s «N4 family», которая также включает оригинальный N5 (5nm), N5P (улучшенный 5nm), N4 (первый 4nm) и N4X (экстремальная производительность). Важно понимать, что N4P — это не переход на совершенно новую технологию (как, например, переход с N5 на N3), а глубокая переработка и оптимизация существующей технологии.
Основная цель N4P: Предоставить разработчикам чипов прирост производительности (P — Performance) при том же энергопотреблении и уровне надёжности, что и у N5, без необходимости кардинально перепроектировать чип.
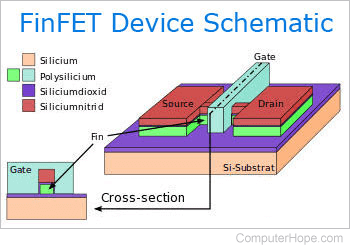
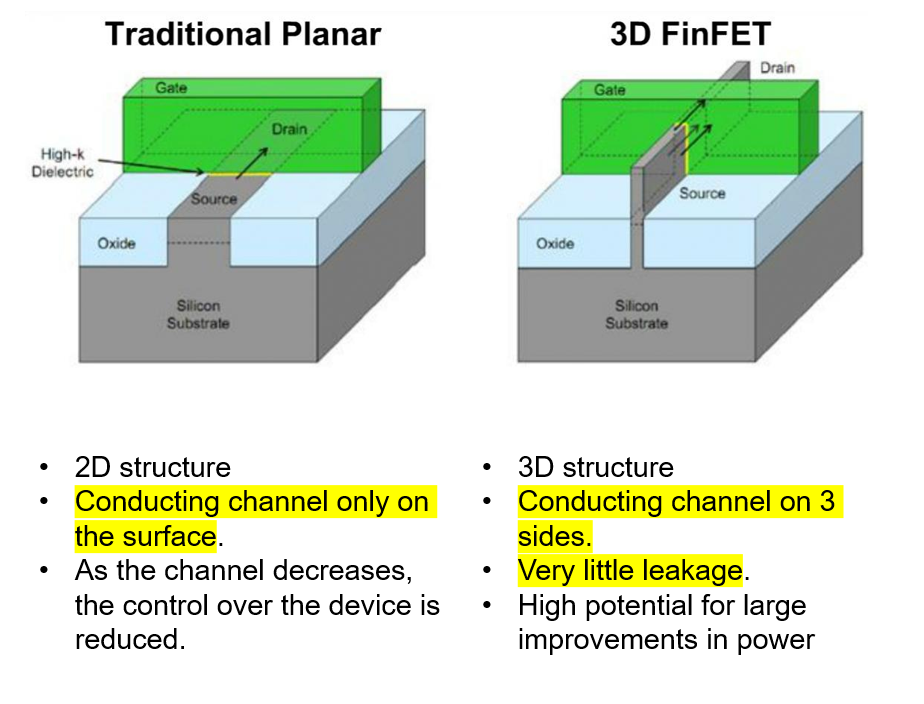
В основе N4P, как и его предшественников, лежат FinFET (транзисторы с трёхмерной структурой «плавник»). Улучшения касаются не изменения фундаментальной архитектуры транзистора, а литографии, материалов и проектных норм. На картинке ниже показано сравнение FinFET с традиционной планарной технологией производства транзисторов. Использование «плавника» приводит к уменьшению токов утечки через затвор.
Основа: N4P использует более совершенную технологию литографии в EUV-слоях (Extreme Ultraviolet Litography) по сравнению с N5 и даже N4.
Влияние на транзисторы:
Основа: Инженеры TSMC оптимизировали doping profiles (профили легирования) и геометрию «плавников» (fins) транзисторов, а также улучшили свойства металлических слоёв для уменьшения сопротивления (R) и паразитной ёмкости (C) в межсоединениях.
Влияние на транзисторы:
Основа: Несмотря на фокус на производительности, N4P также предлагает улучшения в эффективности. Это достигается за счёт более строгих допусков и снижения утечек тока.
Влияние на транзисторы:
По заявлениям TSMC, по сравнению с оригинальным N5 процессом, N4P обеспечивает:
При этом N4P предлагает лучшее соотношение цена/качество и более простую миграцию для дизайнеров, чем переход на N3.
Использование TSMC N4P для CCD-кристаллов Zen 5 (например, в Ryzen 9 9950X) позволило AMD:
Реализовать более сложное ядро: Увеличить количество декодеров, ALU, AGU и других блоков (ядро Zen 5 физически больше ядра Zen 4), не выходя за разумные пределы размера кристалла.
Достичь высоких тактовых частот: Поддержать высокую тактовую частоту, необходимый для рекордной однопоточной производительности, благодаря оптимизированной технологии.
Улучшить энергоэффективность: Частично компенсировать возросшее энергопотребление из-за возросшей сложности ядра. Процессор может работать при более низком напряжении для достижения той же частоты, что и Zen 4, или показывать большую производительность в том же теплопакете (TDP).
Таким образом, N4P не является революцией, а представляет собой идеально сбалансированную эволюцию техпроцесса, которая предоставила AMD необходимый инструмент для создания высокопроизводительных и конкурентоспособных ядер Zen 5 без чрезмерного роста затрат и сложности проектирования.
AMD AGESA (AMD Generic Encapsulated Software Architecture) — это библиотека, разработанная AMD и встроенная в прошивку BIOS/UEFI материнских плат с процессорами AMD. Она инициализирует процессор, память и другие системные устройства, обеспечивая поддержку нового оборудования и исправляя ошибки. Обновления AGESA часто встречаются в примечаниях к выпуску BIOS/UEFI вашей материнской платы, поскольку они критически важны для оптимальной производительности, совместимости и безопасности.
Что делает AGESA:
Вместе с новыми процессорами в BIOS появились и новые настройки для их тюнинга и вольт-моддинга, частично перекочевавшие из Zen 4.
CPU Core Voltage
Как следует из названия, это напряжение питания ядер. Оно напрямую влияет на частоту ЦП и энергопотребление. Обычно оно не влияет на память или другие блоки кристалла.
CPU SOC Voltage (VDDSoC)
Это напряжение питания для cIOD. Не все блоки напрямую используют напряжение VDDSOC.
При разгоне напряжение VDDSOC напрямую влияет на UCLK. Это объясняет, почему обычно возможно работать с более низким напряжением в режиме UCLK = MEMCLK / 2, даже если память работает со скоростью 8000 МТ/с или выше. Как бы это ни парадоксально, этот параметр мало влияет на максимальную частоту памяти или даже на FCLK.
CPU VDDIO
Этот параметр довольно важен для разгона памяти, поскольку его обычно необходимо увеличивать при повышении MEMCLK. Однако между различными экземплярами процессоров наблюдаются значительные различия, и некоторые из них демонстрируют ошибки в тестах стабильности при повышенном напряжении. Как правило, можно достичь 6400 МТ/с при напряжении 1,35 В или ниже и 8000 МТ/с при напряжении от 1,4 В до 1,45 В.
VDDP или CLDO_VDDP
Это напряжение для физических уровней памяти, которое может быть критически важно для тех, кто стремится максимально увеличить частоту MEMCLK. Как и VDDIO, этот параметр значительно варьируется между экземплярами. В среднем, и даже в экстремальных случаях, оно обычно не превышает 1,175 В для частот памяти выше DDR5-8000.
VDDG CCD и IOD
Эта пара параметров относится к напряжениям физических уровней Infinity Fabric, которые соединяют cIOD с CCD. Логично из названия, VDDG CCD находится на стороне CCD, а VDDG IOD — на стороне cIOD. При использовании CPU с двумя CCD можно регулировать напряжение PHY для каждой CCD отдельно.
В предыдущей статье мы рассмотрели, какие встречаются схемы питания в компьютерной технике в целом, а…
В статье рассмотрим, какие бывают схемы питания в материнских платах различных устройств: компьютеров, ноутбуков, планшетов,…
Сегодня в ремонте у нас программируемый терморегулятор теплого пола AC603H c Wi-Fi. Интересно, что одновременно…
Сегодня я успешно сдал экзамены и получил официальный сертификат преподавателя по операционной системе РЕД ОС,…
Мы знаем, что многие привыкли к IPTV сервисам edem.tv, iedem.tv, itook.tv и их зеркалам. Ведь…
Geekbench - пакетов тестов для измерения производительности хостов. Он доступен в разных версиях - 4,…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}