Материал опубликован - 25/12/2001
Технологии материнских плат. Руководство. Часть 1
(слово о процессорах)

Содержание
- Технологии материнских плат. Руководство. Часть 1. (про
процессоры)
- Технологии материнских плат. Руководство. Часть 2. (про
компоненты)
- Технологии материнских плат. Руководство. Часть 3. (продолжаем разговор о компонентах
и на основе полученных данных сравниваем МП Intel D815EEA и Asus A7M266)
Что к чему
В настоящее время компьютерная техника достигла такого уровня, что благодаря многолетним улучшениям и нововведениям, а также при наличии огромного количества литературы на прилавках магазинов и в Интернет, собрать компьютер из различных компонентов может хоть и не любой человек, но достаточное количество искушенных пользователей. Они вполне способны самостоятельно правильно выбрать именно ему необходимые компоненты, все сконфигурировать и настроить. Занятие системным инженерингом - вот то, что волнует умы множества людей, которые по-настоящему стремятся к получению прежде всего своего собственного эффективного и доступного по цене компьютера, и, конечно же, практических навыков по сборке и наладке аппаратуры.
Ремарка: Перед прочтение этой статьи советуем прочитать "Руководство по материнским платам".
Что же является основой любого персонального компьютера? Правильно, материнская плата. Именно она является главным звеном, объединяющим все компьютерные компоненты; она определяет работу процессора и памяти, распределяет все информационные потоки компьютера, и управляет питанием каждого компонента. Именно о материнских платах и пойдет речь в этой статье: мы подробно рассмотрим работу материнских плат последнего поколения. Мы постараемся быть объективными при обзоре каждой системы, будь это система для процессоров AMD, или Intel. Будут рассмотрены все компоненты материнских плат, включая компоненты, которые были разработаны совсем недавно.
Следует предостеречь тех читателей, которые ждут от этой статьи методологии разгона: этого не будет. Статья посвящена основным параметрам материнских плат, различиям в их архитектуре и их работе с новейшими процессорами.
Перед тем, как перейти непосредственно к различиям и особенностям материнских плат, необходимо немного времени уделить общей концепции архитектуры современных ПК. Это поможет в дальнейшем лучше понять новые технологии материнских плат.
Скорость и сбалансированная планировка
В современном ПК абсолютно все компоненты передают и принимают данные… Передача данных должна происходить очень быстро, иначе сойдет на нет вся производительность системы в целом.
Центральный процессор - сердце любого ПК. Он претерпел огромные изменения со своего первого применения: первый процессор для IBM PC - Intel 8088 работал на частоте 4.77 МГц, имел 16-битную внутреннюю архитектуру, и 8-битную шину данных. Современные процессоры имеют 32-битную внутреннюю архитектуру, успешно перевалили частоту 1 и 2 ГГц, а шина данных стала 64-битной.
Как видите, разработчики ЦП (центральный процессор) приложили немало усилий для улучшения процессоров… Но величина тактовой частоты процессора в любом случае хоть и важный, но не главный фактор: производительность компьютера определяется всеми компонентами компьютера в целом, увеличение же тактовой частоты не всегда означает автоматическое увеличение производительности. В зависимости от процессора, работа при выполнении одного такта может различаться.
В процессорах Athlon за один такт микропроцессора выполняется 9 различных операций. Процессор Pentium 4 выполняет небольшое количество некоторых операций АЛУ (арифметико-логическое устройство) на двух устройствах - получается, что эффективно количество операций за такт удваивается. Современные процессоры могут выполнять миллиарды таких тактов в секунду, что и используют для своей работы другие компоненты компьютера, и, конечно же, пользователи.
Разработка процессоров ведется уже давно, но они все равно производят лишь общие математические операции, перенос данных, а также операции сравнения. Производительность системы в последнее время определяется выполнением различных мультимедиа операций: это обработка графики, звука и видео. Такой тип операций нуждается в очень быстром переносе большого массива данных через всю систему с различными расчетами и выводами результата.
Сбалансированная планировка
Все эти расчеты графики, видео и звука, очень "прожорливы": иногда требуется практически вся мощность компьютера. В такой ситуации для проектировщика очень важно создать полностью сбалансированную систему, когда возможности процессора по обработке данных не тормозятся низкой пропускной способностью памяти. Ведь если пропускная способность памяти будет недостаточной, процессор просто вовремя не получит необходимые ему данные, а в результате - будет некоторое время простаивать. Это естественно приведет к потере потенциальной производительности.
Интересен и такой момент: некоторые процессорные компании, такие как Intel (а именно Intel Architecture Labs), сознательно увеличивают напряжение на системных компонентах для того, чтобы они работали быстрее, даже если это компоненты других фирм.
Ремарка Hardvision: Надо заметить, что такие методы увеличения производительности не бесконечны. Положение таково, что кристаллы, из которых состоит каждый из применяемых на сегодняшний день процессоров, имеет свою критическую температуру нагрева. Так вот при данных размерах кристаллов, которые производятся по технологическим процессам 0.13, 0.18, а в 2002 году и по 0.09 микрон охлаждение обычным кулером с радиатором вполне хватает, но при переходе на 0.03 микрон эта самая критическая температура кристалла достигнет своего апогея и они просто-напросто сгорят. Тоже самое может произойти и при повышении напряжения на ядре процессора. Причем ни на воде, ни на жидком азоте радиаторы на смогут охладить кристаллы до уровня нормально производительности или же это будет чересчур дорого и не рационально. И в следствии всего вышесказанного производителям придется переходить на принципиально новые методы производства процессоров.
Для улучшения ситуации с пропускной способностью, и Intel, и AMD предлагают и помогают внедрять все новые и новые системные архитектуры для обеспечения нормальной работы быстрых процессоров. Кроме того, компьютерные энтузиасты для увеличения производительности компьютера используют специальное внешнее оборудование, что в последнее время очень критикуется компанией Intel. Но вернемся к материнским платам. Инженерам-разработчикам необходимо создавать сбалансированные материнские платы, которые бы обеспечивали нормальную пропускную способность не только между процессором и памятью, но и для всей системы. Современные материнские платы очень различаются в системной архитектуре, но есть и общие принципы, о которых мы и расскажем в следующей главе.
Кэш-память: мощность и ограничения
От быстрого к медленному: Иерархия компьютера
Для начала рассмотрим такую важную часть системной архитектуры, как кэш-память. Кэш-память, находящаяся в самом ядре процессора (во всех современных процессорах) - это самая быстрая память, в которую помещается информация, которая необходима процессору. Первым делом процессор обращается к кэш-памяти 1 уровня при отсутствии нужной информации, он обращается к кэш-памяти других уровней или берет ее из оперативной памяти.
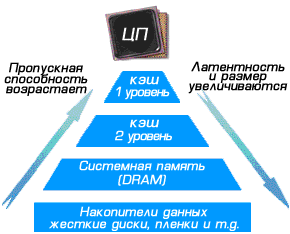
Иерархия памяти
Рисунок выше наилучшим образом помогает представить принцип взаимодействия процессора, кэш-памяти, оперативной памяти и устройств хранения информации. Чем ближе к процессору, тем емкость памяти уменьшается, а скорость - увеличивается.
Нормальное значение производительности компьютера зависит от хорошо спроектированной и реализованной архитектуры памяти, которая должна быть спроектирована так, чтобы на других этапах передачи данных не возникало перегрузок и застоев в передаче данных.
Различные реализации кэш-памяти
До материнских плат поколений Pentium II, или Athlon, кэш-память второго уровня располагалась не на ядре (или плате, как в Pentium II и ранних Pentium III и Athlon для Slot1 и SlotA) процессора, а выполнялась в виде обычной SRAM и располагалась на материнской плате. Но с повышением производительности процессоров возникла острая необходимость ускорить работу кэш-памяти второго уровня, именно поэтому она и перекочевала в ядро процессора (или на его плату - как уже говорилось). Сейчас идут разработки для добавления еще одного уровня кэш-памяти - Level 3 cache, который будет встроен в материнскую плату.
Кэш-память, размещенная в ядре процессора всегда гораздо быстрее и мощнее памяти, размещенной на материнской плате. Кроме того, кэш, размещенный в ядре процессора, обладает следующим свойством: он работает одновременно и с данными, и с инструкциями для процессора (по различным историческим причинам такая архитектура была названа Гарвардской - "Harvard Architecture").
Как показало время, размещение кэш-памяти на ядре процессора, было очень удачным шагом: разработчики получили возможность использовать гораздо более широкий интерфейс кэша. Даже в процессоре Pentium за такт передается 256 бит (32 байт) инструкций для процессора. Эти 256 бит в Pentium это строка кэша (английский термин - cache line) (наименьшая единица информации, которая может быть записана в кэш). Каждая линия имеет дескриптор кэша (английский термин - cache tag), который обеспечивает разделение на строки КЭШа при очередном удачном обращении в него.
Кроме того, с введением встроенного в ядро кэша, стало возможным встраивать в кэш большее количество комплектов так называемой ассоциативной памяти (английский термин tag memories), что делает кэш более доступным и значительно снижает потери и неудачные обращения в кэш. В этой концепции есть и маленький минус: встраивание большого количества комплектов ассоциативной памяти в кэш непременно влечет увеличение стоимости кэш-памяти, а также значительно ее усложняет. К примеру, кэш с одним комплектом такой памяти называется "1-путным", или "кэш прямого отображения". Если же кэш с 4 комплектами ассоциативной памяти, то он называется "4-х путным" ("4-way"). Компьютерные архитекторы уже давно дискутируют, что же выбрать: производительность, или дешевизну… но больший объем кэш-памяти и количество комплектов ассоциативной памяти в КЭШе на производительность влияют очень сильно: она значительно увеличивается.
Еще одно преимущество встроенного КЭШа - такая кэш-память может иметь несколько портов ввода/вывода, что позволяет ядру ЦП производить синхронное чтение (англ. термин simultaneous read) и доступ к записи (англ. термин write access) (подобно доступу к различным конвейерам). В некоторых процессорах применяется и многопортовая ассоциативная память. Эти дополнительные порты также встроены в ядро. Питание кэш-памяти зависит от всех ее компонентов и ее объема: чем больше количество компонентов КЭШа и объема кэш-памяти, тем больше необходимо затратить энергии.
Кэш память большего объема оказывается, как правило, медленнее, т.к. ее заполнение занимает большее количество времени (кроме того, ей необходимо большее питание). Именно поэтому размер кэш-памяти первого уровня (Level 1 cache) гораздо меньше, чем кажется разумным. К примеру, процессор Pentium4 имеет всего 8 Кб кэш-памяти 1 уровня плюс 12 Кб предварительного КЭШа выполнения пути (Execution Trace Cache), который выполняет такую же роль, как и кэш-память первого уровня для инструкций.
Дизайнеры Intel все время стремятся увеличить размер кэш-памяти, но сложность и дороговизна производства процессоров вынуждает пойти на компромисс между мощностью и стоимостью.
Настоящий враг - латентность памяти (Memory Latency)
Следует знать и архитектуру памяти - ведь она является одним из главных компонентов компьютера, от которой также сильно зависит производительной всей системы. Как правило говоря о памяти, мы зацикливаемся на таких ее параметрах, как частота, пропускная способность и время доступа к ней, но совершенно упускаем из вида проблему латентности (время ожидания, задержка) памяти. Различные нововведения, такие как встаивание кэш-памяти в ядро процессора и т.п. сделаны для увеличения пропускной способности памяти, но они не уменьшают латентность. От латентности невозможно избавиться: с каждым увеличением тактовой частоты процессора, увеличивается и латентность. Единственный выход - это менять саму память.
С каждой стадией иерархии памяти появляется и большая латентность. Устройства, находящиеся вне ядра процессора имеют просто огромные значения латентности, т.к. они получают доступ к процессору только через относительно медленную память DRAM (Dynamic Random Access Memory). Новые технологии памяти DRAM, такие как RDRAM, хоть и имеют огромную частоту работы, но сложность самой памяти, а также шины все же увеличивают среднюю латентность системы.
Чтобы показать актуальность и важность проблемы латентности, приведем такой пример: латентность из-за встроенной в ядро кэш-памяти на быстрых системах приблизительно составляет 80 процессорных циклов!
Выход из ситуации
Но не все так мрачно, как кажется. Архитекторы процессоров адаптируют свои детища для неизбежной работы с латентностью. Хорошо спроектированный, быстрый кэш - большая часть решения проблемы: по статистике, каждая третья операция процессора - это операция с памятью. Но каждая 5 инструкция это одна из разновидностей операций условного перехода, что делает кэширование очень непростой задачей, т.к. процессору очень трудно определить, что же необходимо кэшировать, а что - нет. Именно поэтому производители процессоров наперебой хвастаются реализацией в их процессоре алгоритма прогнозирования ветвлений, т.к. плохой прогноз приводит к потери уже загруженной памяти и загрузке новых данных, что замедляет работоспособность.
Лучший выход из сложившейся ситуации с латентностью памяти - это полностью избегать эти огромные потери в кэш-памяти. Подход к решению проблемы был позаимствован у процессоров Centaur (теперь это процессоры Via Cyrix) - передать большое количество транзисторов управлению кэш-памятью, а также на лучшую реализацию операций предсказания ветвлений. Такое решение оказалось очень кстати в свое время, наконец-то был найден баланс между иерархией памяти и низкой стоимости при довольно хорошей эффективности системного дизайна.
Большое изменение в архитектуре процессора началось, когда было пересмотрено традиционное внутреннее выполнение потока. Вместо него Intel стала использовать внешнее, динамическое выполнение. Первым процессором, работающим по новой схеме, стал процессор Intel Pentium Pro, архитектура которого позволяла выполнять инструкции в таком порядке, что ресурсы для вычислений, доступны пока инструкции полностью не освободятся от связей. Процессор Pentium 4 может выполнять "на лету" 126 инструкций, что позволяет процессору одновременно и выполнять операции с большой задержкой (латентностью), и искать те инструкции, которые понадобятся для выполнения позже.
Архитектура процессоров AMD Athlon использует похожий подход к решению проблемы с латентностью. Отличительная особенность в архитектуре этого процессора заключается в том, что память не разбивается на блоки при загрузке, что позволяет загружать в процессор данные в то время, когда он ожидает данные, задержанные латентностью.
Как латентность обходится в шине материнской платы
Вместе с разработками новых процессоров класса Pentium Socket 7 разработано решение по уменьшению задержек латентности и увеличении пропускной способности шины. Все процессоры Intel Pentium Pro, Pentium II, Pentium III и Celeron используют 64-битную, полностью конвейеризированную шину с разделением транзакций (шина P6).
При работе с перекрытием запросов памяти, процессор способен более эффективно управлять шиной и сохранять ее оперативность даже при выполнении операций с большими задержками (латентностью). Тут все точно также: одновременно с ожиданием данных, задержанных латентностью, шина может отправлять и принимать данные для других операций с памятью, или вода/вывода.
Немного позже Intel полностью изменила дизайн материнской платы касаемо процессора. Сам процессор также претерпел изменения: кэш-память второго уровня была вынесена за ядро и размещалась на специальной плате, которая и вставлялась в материнскую плату через новый разъем Slot-1. Такой разъем использовался процессорами Pentium Pro, Pentium II, а также ранними Pentium III (на ядре Katmai). Интеграция кэш-памяти второго уровня на специальную плату отодвинуло системную шину по иерархии памяти ниже, что позволило сбалансировать дизайн. Это было очень удачным решением для своего времени: при введении такой архитектуры системная шина работала на частоте 100 МГц, не вызывая больших задержек. Затем процесс производства процессоров позволил применить накопленный на Slot-1 опыт и переместить кэш-память второго уровня обратно на ядро процессора. Это стало началом конца Slot-1 материнских плат. Был разработан новый стандарт для соединения материнской платы и процессора - Socket 370 (370 означает количество штырьков, контактов), который позволил увеличить частоту шины до 133 МГц. Следует отметить, что общий принцип работы шины не изменился. На такой шине работают процессоры Pentium III и основанные на нем Celeron, а также процессоры низкого класса VIA Cyrix.
AMD, Intel и… цифровое оборудование?
Шина AMD и DEC
Вместо того, чтобы использовать шину P6, AMD лицензировала хорошо спроектированную шину EV6 от Compaq Computer Digital Equipment Corp. Эта шина изначально была создана для обеспечения потрясающей пропускной способности для процессоров Alpha RISC, и моментально дала процессорам Athlon именно ту необходимую мощь, которая исчезала у конкурентов в сильно загружающих память приложениях.
В то время чипсеты, созданные для Athlon, не могли работать с подсистемой памяти также быстро, как процессор работал с чипсетом, что естественно приводило к несбалансированности системного дизайна. Более поздние чипсеты решили эту проблему, вернув недостающую стабильность системы.
Теперь о внутреннем устройстве. Шина P6 - это классическая разделяемая шина, где все устройства разделяют одни сигналы. Шина EV6 - переключаемая, т.е. каждое устройство открывает собственный канал, по которому информация передается на манер разделения транзакций. Одновременно шина EV6 может работать с 24 транзакциями (эффективность работы шины P6 можно сравнить с 8 транзакциями), что естественно снижает латентность.
Но основное преимущество шины EV6 заключается в ее огромной пропускной способности, которая возникает благодаря тому, что адреса и данные передаются за цикл одновременно (при использовании памяти DDR - Double Data Rate DRAM, о которой поговорим немного позже), если частота времязадающего генератора была 100 МГц, эффективная частота работы шины EV6 получалась 200 МГц (у современных Athlon - 266 МГц - у них частота времязадающего генератора 133 МГц). А вот и цифры: пиковая пропускная способность шины EV6, работающей на частоте 266 МГц составляет 2.1 Гб/сек. Теперь сравните с шиной P6, работающей на частоте 133 МГц: пропускная способность составляет 1.06 Гб/сек.
Первая реализация шины AMD EV6 была реализована, как и у конкурента, для процессора, находящегося в специальном картридже, который представлял собой плату, на которой были размещены сам процессор, различные вспомогательные компоненты и кэш-память второго уровня. На материнской плате такой разъем назывался Slot-A. Немного позднее процессор также стал выполняться в Socket-реализации со встроенной в ядро кэш-памятью второго уровня. Название этого разъема - Socket A (первое название - Socket 462). Такой тип шины работает на частотах 200/266 МГц с процессорами Athlon, Athlon XPи Duron.
Ответ Intel: Pentium 4
Все ждали ответа Intel. Им стал выход процессора Pentium 4, который работает с совершенно другой архитектурой системной шины. Ее устройство имеет множество сходств с шиной EV6. Она также синхронизирована от источника, но за цикл в ней передается 2 адреса, и 4 кусочка памяти размером по 64-бит (8 байт). Таким образом, если частота времязадающего генератора равна 100 МГц, эффективная частота шины получается 400 МГц. Пиковая пропускная способность шины тогда равна 3.2 Гб/сек (400 МГц х 8 байт).
Особо любознательные могут задать вполне резонный вопрос: как чип передает данные 4 раза за такт, когда времязадающий генератор шины задает всего 2 фронта импульсов? Ответ заключается в том, что при передачи данных по шине используется специальная система автоматической подстройки по задержке (delay-locked loop - DLL), которая специальным образом синхронизирует частоту такта и меняет точку выборки данных (в данном примере это позволяет создать нормальные условия для передачи информации во фронтах импульсов для передачи данных 4 раза).