Как известно, для всего у Intel есть кодовые наименования — для технологий, платформ, ядер, семейств. Эта статья нацелена на то, чтобы во всем этом обилии наименований не запутаться. Много времени прошло с момента публикации нашей аналогичной статьи по кодовым наименованиям процессоров, покрывавшую 2005-2008 года выпуска. После этого у нас была опубликована статья о планах процессорного гиганта и технологического лидера Intel на 2009 год.
Как и было обещано, мы получили платформу Nehalem (до нее была Core второго поколения), на базе которой было выпущено несколько семейств процессоров на разных ядрах. Зато вот разных семейств процессоров на данной архитектуре появилось множество. В них мы и будем разбираться.
Позволю себе напомнить, что Intel выпускает все продукты по схеме «Тик-Так» (Tick-Tok): каждый тик — это появление нового техпроцесса и выпуск процессоров на нем, используя имеющуюся архитектуру, а каждый так — это появление новой архитектуры (второе поколение, если хотите). Такая схема с одной стороны позволяет оптимизировать существующие архитектуры и выжать из них максимум на втором этапе, а с другой — подготовиться к выпуску новой архитектуры. Весь цикл длится примерно 2 года, по году на каждую стадию.
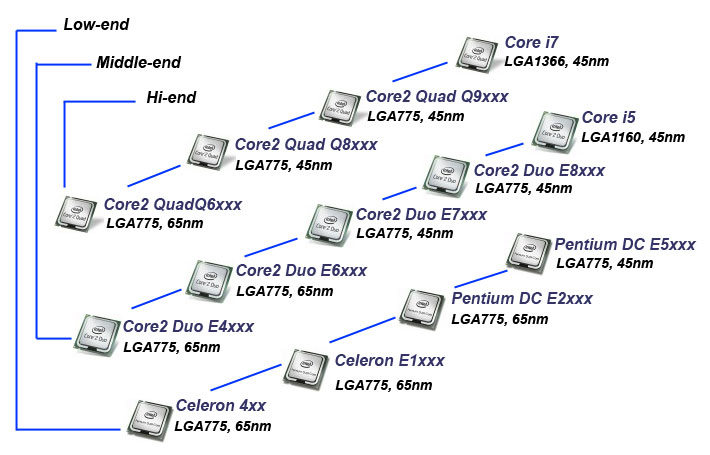
Итак, до 2009 года картина выглядела следующим образом:
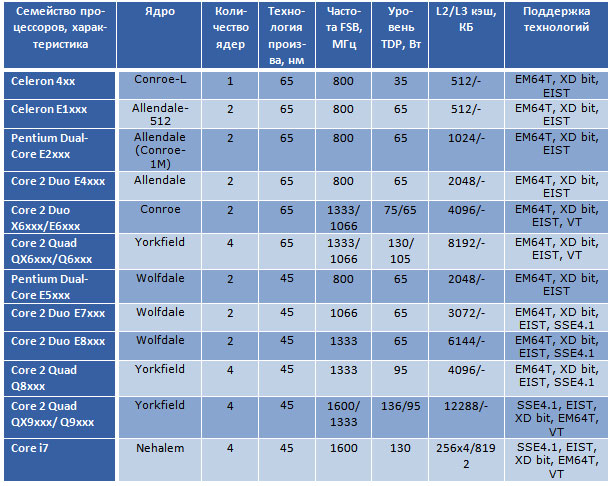
Penryn — кодовое название 45-нанометровой производственной технологии от компании Intel с использованием металлических затворов Hi-k без содержания свинца. Эта технология используется в семействе процессоров Intel Core 2 Duo. Эти процессоры основаны на архитектуре Core. Таким образом, основой архитектуры Core были процессоры на ядрах Conroe, Allendale (урезанный Conroe), Wolfdale (урезанный Yorkfield) и Yorkfield. В этом случае Intel Core — это «так», а Penryn — это «тик».
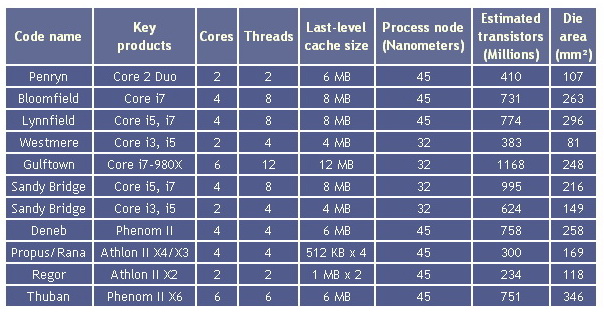
Пришедшая на смену Core архитектура Nehalem, была представлена в 4 квартале 2008 года и принесла большие изменения в настольную архитектуру: встроенный 2 и 3 канальный контроллер памяти DDR3, масштабируемую шину QPI, кэш 3 уровня. Самое же главное отличие с технологической точки зрения — интеграция всех 4 ядер в один кристалл, как у AMD. Техпроцесс старый, «пенруновский» — 45 нм.
В рамках этой архитектуры создано 2 ядра: Bloomfield в исполнении LGA 1366 (Socket B) и Lynnfield в исполнении LGA 1156 (Socket H). Микропроцессоры продаются под торговой маркой Core i7 и Core i5 соответственно. Понятно, что в Lynnfield вместо шины QPI использовалась урезанная DMI, на что указывает меньшее число контактов в сокете. Интересно, что Core i5 выпускались только на ядре Lynnfield (всего 3 с маркировкой 7xx), а Core i7 — на обоих ядрах (маркировки Core i5-6xx, Core i7-8xx и Core i7-9xx). Все эта ядра производились год и, как и предполагалось по плану, уступили место «таку».
Для мобильных процессоров 45-нм ядро архитектуры Nehalem называлось Clarksfield. На его базе в 2009-2010 годах были выпущены процессоры Core i7-7xxM/8xxM/9xxM, всего 6 моделей.
Технологический барьер 32 нм необходимо было преодолеть обязательно. Ведь за этим скрывался рывок к новым возможностям кристаллов, которые ранее Intel планировала, но не могла использовать. Итак, через год в конце 2009 г. была представлена вторая реинкарнация Nehalem под названием Westmere, основанная на техпроцессе 32 нм. Она дала путевку в жизнь сразу всем сегментам рынка настольных и мобильных процессоров. На базе это архитектуры представлены ядра:
Встроенное в Core i3/i5 графическое ядро, конечно достаточно слабое по сравнению с тем, что встроено в AMD A6/A8, работает на частоте 733 МГц и выполнено по техпроцессу 45 нм. Также, все эти процессоры поддерживают технологию Intel Turbo Boot — саморазгона процессора при условии незагруженности части ядер за счет изменения множителя базовой частоты тактового генератора (BCLK, равная 133 МГц). Сами процессоры появились в продаже только в первой половине 2010 года.
Потом в серийное производство вошел флагманский дизайн ядер данной архитектуры — Gulftown, он обладает шестью ядрами, двенадцатью потоками, 12 Мб общего кеша третьего уровня, системной шиной QuickPath Interconnect (QPI), но несмотря на это, его энергопотребление не превышает 130 Вт. Он требует сокет LGA1366 и набор системной логики Intel X58 Express. Фактически этот дизайн представляет собой полтора чипа с дизайном Bloomfield на одной подложке, произведенной с соблюдением норм 32-нм техпроцесса. Процессоры Core i7-970 и 980X были выпущены в середине 2010 года, в то время как 980 и 990X только через год. Это связано в тем, что в 2010 году Intel продолжала производить кристаллы Bloomfield (Core i7-930) и Lynnfield (Core i7-860S/870S/880), которые и так успешно лидировали на рынке. К тому же, был произведен один процессор для экстрималов с разблокированным множителем — 875K.
Справка: QPI является последовательной высокоскоростной двунаправленной (дуплексной) шиной. Ее ширина в каждую сторону (передача и прием) составляет по 20 бит (20 отдельных пар линий), при этом 16 бит отводится для передачи данных, две линии зарезервированы для передачи служебных сигналов и еще две — для передачи кодов коррекции ошибок CRC. C учетом еще двух пар линий, используемых для синхронизации сигналов (одна на прием и одна на передачу), получаем, что шина QPI состоит из 42 пар линий, то есть является 84-контактной. Теоретическая пропускная способность шины QPI составляет 25,6 Гбайт/с, хотя такая единица измерения, как гигабайт в секунду (Гбайт/с), не используется в качестве характеристики QPI-шины. Вместо этого применяется термин «трансферы в секунду» — количество передач запакетированных данных по шине в секунду. В таких единицах измерения максимальная пропускная способность шины QPI составляет 6,4 GT/s.
DMI по своей идеологии аналогична QPI за исключением количества линий связи. Для связи процессора с чипсетом обычно используется 4 канала DMI (x4 link), обеспечивающих максимальную пропускную способность до 10 Гбайт/с для ревизии DMI 1.0 в каждом направлении, и 20 Гбайт/с для ревизии DMI 2.0, представленной в 2011 году. В бюджетных мобильных системах может использоваться шина с двумя каналами DMI, что в два раза снижает пропускную способность по сравнению с 4-х канальным вариантом.
Часто в процессоры, использующие связь с чипсетом по шине DMI, встраивают, наряду с контроллером памяти, контроллер шины PCI Express, обеспечивающий взаимодействие с видеокартой. В этом случае надобность в северном мосте отпадает, и чипсет выполняет только функции взаимодействия с платами расширения и периферийными устройствами. При такой архитектуре материнской платы не требуется высокоскоростного канала для взаимодействия с процессором, и пропускной способности шины DMI хватает с избытком.
Westmere добрался и до мобильных кристаллов. Для них было представлено ядро Arrandale. Причем, на базе него выпущены мобильные процессоры всех трех линеек — двухядерные Core i3/i5/i7 (вот развлечение то производителям и покупателям ноутов!). Частота GPU во всех снижена и может динамически варьироваться с пределах 166-500 МГц (ULV), 266-566 (LV), 500-766 МГц во всех остальных. В Core i3 поддержки Turbo нет, а Core i7 в отличие от настольной модели использует, как и прочие, шину DMI вместо QPI. Также, Core i3 имеют меньший по отношеню к остальным кэш L3 объемом 3 МБ и исполняются в корпусе PGA988. Остальные же изготавливаются в BGA-1288/Socket G1.
Также, стоит отметить, что все мобильные процессоры используют встроенный контроллер памяти DDR3-1066 против DDR3-1333, как у настольных собратьев.
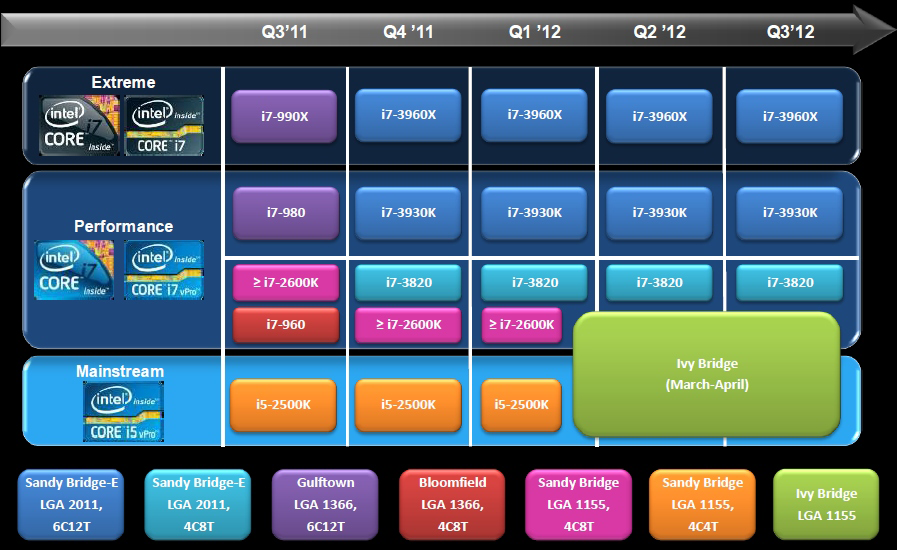
Строго следуя своим часам, которые «тикают и такают» раз в год, в начале 2011 года Intel представила новую архитектуру Sandy Bridge. До конца 2011 года все процессоры были переведены на эту архитектуру. Несмотря на это не внушающее доверия название («Песочный Мост»), архитектура действительно революционна (вот уж где давно пора было Intel проявить мощь своего научного потенциала)!
Ни для кого давно не секрет, что половина успеха производительности процессоров — оптимизация программного кода с учетом архитектуры самих процессоров. Это и учет длины конвейера, и эффективность работы механизма предсказания ветвлений, и количество регистров, эффективность их использования в многоядерных системах. Понятно, что в большинстве задач ресурсы процессора (регистры, кэш) далеко не всегда эффективно загружены. В общем и целом, все сводится к тому, что эффективность работы того или иного приложения зависит напрямую от того, каким компилятором пользовались создатели, какой набор команд был задействован, особенно это касается мультимедиа софта. Кодерам необходимо писать новое ПО используя новые версии компиляторов и тулов от Intel, которые помогают найти «бутылочные горлышки» при выполнении кода.
Так вот, существующая архитектура x86-совместимых процессоров изначально ограничивала возможности программистов по эффективному использованию ресурсов. И главное ограничение — сам набор и формат команд x86. Все один двухоперандные, то есть позволяют выполнять операции только с двумя операндами. 128-битных инструкций SSE4.2 уже давно не хватает — они поддерживали до 4 32×32 битных умножений за одну инструкцию; позволяли удобно выполнять скалярное произведение в массивах данных с одинарной и двойной точностью, что удобно при обсчете 3-мерных координат в играх, например, а также эффективнее работать с регистрами GPR (регистры общего назначения) или памятью и регистрами XMM, что было особенно полезно при векторизации изображений и работе с видео; также они значительно повысили эффективность работы с текстом. Но все эти команд упирались в структуру регистров и их разрядность. Каждый регистр XMM может содержать четыре 32-битных значения с плавающей точкой одинарной точности.
Впервые в Sandy Bridge Intel решилась на серьезное усовершенствование архитектуры x86-64 со времен SSE (напомню, в SSE было 16 128-битных регистров XMM0-XMM16). Компания представила новые 256битные инструкции и новая система их кодирования, названная Advanced Vector Extensions (AVX). Для этого разрядность регистров была также увеличена до 256 бит, которые названы YMM0-YMM15. Существующие 128-битные SSE инструкции будут использовать младшую половину новых YMM регистров, не изменяя старшую часть.
Набор AVX инструкций использует трёхоперандный синтаксис. Например, вместо a=a+b можно использовать c=a+b, при этом регистр a остаётся неизменённым. В случаях, когда значение a используется дальше в вычислениях, это повышает производительность, так как избавляет от необходимости сохранять перед вычислением и восстанавливать после вычисления регистр, содержавший a, из другого регистра или памяти. Для большинства новых инструкций отсутствуют требования к выравниванию операндов в памяти (выравнивание размещения операндов в памяти относительно адресов ими занимаемых). В целом, AVX предназначен для интенсивных вычислений с плавающей точкой в мультимедиа программах и научных задачах, особенно при работе с вещественными числами. Понятно, что это серьезное нововведение заметно только после перекомпиляции кодов с поддержкой AVX.
Вторым серьезным нововведением стало появление кэша нулевого уровня L0, который предназначен для хранения декодированных микроопераций (МОП). Он должен увеличить производительность и энергоэффективность за счет буферизации всех МОП, полученных после преобразования инструкций x86. И если входной поток команд содержит совпадения с ранее декодированным, то результаты работы декодера загружаются сразу из кеша L0. При этом цепи декодеров, которые являются сложной и «прожорливой» частью x86 процессоров, выключаются. Емкость L0 – 1536 МОП, что эквивалентно 6 КБ кеша инструкций (L1) при размере команды 4 байта. По оценкам Intel, степень попадания в L0 составляет примерно 80 %, так что в его эффективности сомневаться не приходится.
Еще одна доработка, о которой долго в этой статье рассказывать не буду — совершенствование GPU используется или Intel HD Graphics 2000 или 3000 и интеграция контроллера PCI Express 2.0 в единый кристалл CPU.
В 2011 году Intel выпустила огромное разнообразие процессоров на ядре Sandy Bridge во всех продуктовых линейках. Радует то, что компания не стала мудрствовать лукаво и не стала каждому семейству давать отдельное кодовое имя. Все процессоры используют разъем LGA1155 (ура!)
Все Core i3 имеют 2 ядра на кристалле, не поддерживают Intel Turbo, используют шину DMI 2.0. TDP от 35 до 65 Вт.
Обновленные Core i5 имеют 4 ядра (кроме 2390T), отличаются в два раза большим кэшем L3 — 6 МБ и включенной поддержкой Turbo. Как следствие, TDP у них лежит в пределах от 45 до 95 Вт.
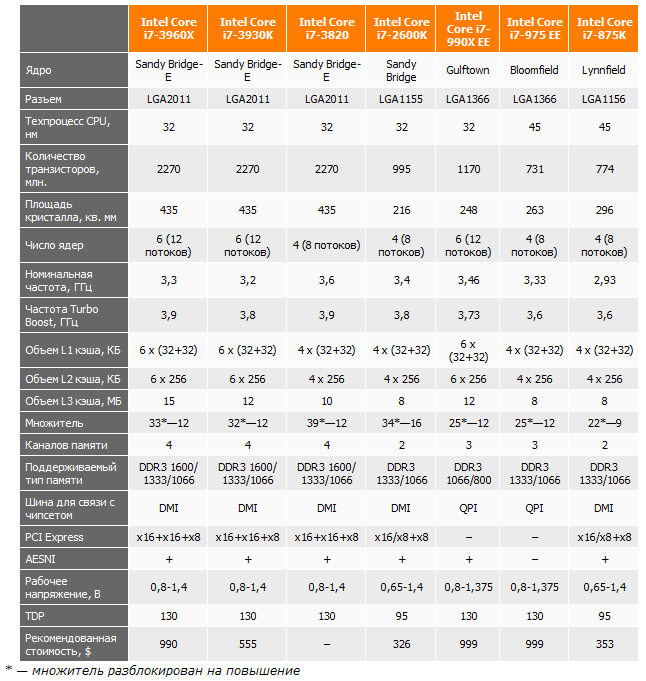
C Core i7 все сложнее — здесь царит разнообразие. Процессоры Core i7-2xxx имеют встроенное графическое ядро, которого у более производительных 3xxx нет. 2xxx семейство имеет кэш L3 объемом 8 МБ и потребляет до 95 Вт.
Семейство 3xxx основано на усовершенствованном ядре Sandy Bridge-E. Отличается оно от младших моделей значительно: наличие 6 ядер вместо 4 в одном кристалле; отсутствие встроенной графики, новый разъем LGA2011 (Socket R); объем кэша так вообще в каждой модели разный — 10, 12 и 15 МБ. Кристалл имеет контроллер памяти с поддержкой до 4 каналов памяти. Кристаллы естественно получились большими и горячими — 2.27 млрд. транзисторов и TDP до 150 Вт у топовой модели Core i7 Extreme Edition 3970X! Она будет представлена на этой неделе, 16 ноября этого года.
Многим интересно, что же делать с уже устаревшими за всего лишь за год топовыми 990x — неужели разница действительно ощутима? По набору тестов, в среднем, Core i7-3960X превосходит бывшего лидера Core i7-990X на ядре Gulftown на 15-20% (в синтетических тестах 3DMark11 разрыв в 36%), что значительно. Такой прирост в топовой производительности за год можно считать гигантским, что заставляет задуматься, а надо ли вообще сейчас то-то покупать до выхода более «холодной» Ivy Bridge-E, раз движение идет такими семимильными шагами?
Но и это еще не все: Sandy Bridge гораздо более плодовита. Также выпущено 9 моделей процессоров Pentium G6xx/G8xx и Celeron G4xx/G5xx. Все они, как и Core i3, не поддерживают Turbo, отличаются разной частотой GPU, объемом кэша L3 от 1 до 3 МБ и поддержкой разных стандартов частоты контроллера памяти. Pentium G8xx поддерживает DDR3-1333, все остальные — DDR3-1066. Причем, Celeron G4xx имеют всего 1 ядро — казалось бы, кому сейчас это надо, ведь даже у всех Atom всех 2 ядра 4 потока? Цель проста — снизить энергопотребление настольных процессоров до 35 Вт. Весьма спорный продукт для «стола», вроде бы бюджетные настольные системы и так уже тихие и холодные, а разница в цене между одно и двухядерным Celeron всего 5 у.е. На самом деле, замысел становится ясен после внимательного изучения линейки. Дело в том, что Intel сейчас не выпускает Celeron с TDP 45 W: следующий за 35-ватовым G465 сразу идет G530 с термопакетом 65 Вт, многовато для офисной печатающей машинки. Для этого и пришлось «отрезать» одно ядро. Хотя бы Hyper-Treading оставили, и то хорошо.
Ситуация с мобильными Sandy Bridge аналогична настольным — они отличаются частотой, меньшим объемом кэша, меньшим числом ядер. Вообщем все сделано для уменьшения числа транзисторов и, следовательно, тепловыделения. TDP лежит в пределах от 17 (у Celeron и младших Core i3) до 55 Вт у Core i7 Extreme Mobile. На мой взгляд оптимальным соотношением производительности на Вт энергопотребления обладает Core i3 2367M @ 17 W и Core i5 2435M @ 35W. Все мобильные процессоры, за исключением Celeron и Pentium, используют графическую подсистему Intel HD 3000 (с 12 универсальными процессорами).
Про серверные даже говорить здесь не хочется — таково разнообразие продуктов на платформе Sandy Bridge. Представлены модели во всех возможных сокетах, от 2 до 8 ядер, с контроллерами памяти о 1333 до 1600 МГц. Младшие 2 и 4 ядерные модели имеют встроенные граф. ядро. Средние или старшие Xeon E5 его уже просто «не тянут» по TDP. Напомню, что главное отличие процессоров на LGA 2011 от LGA 1356 (Socket B2 — модифицированный LGA 1366, Socket B) — наличие у первого 2 шин QPI и 2 дополнительных линий для PCI-E 3.0 у первого. К тому же, LGA 1356 поддерживает только 3 канала памяти против 4 у LGA 2011.
Младшие серверные модели Xeon E3 вообще используют LGA 1156 (Socket H), так как у них задействовано только 2 канала памяти.
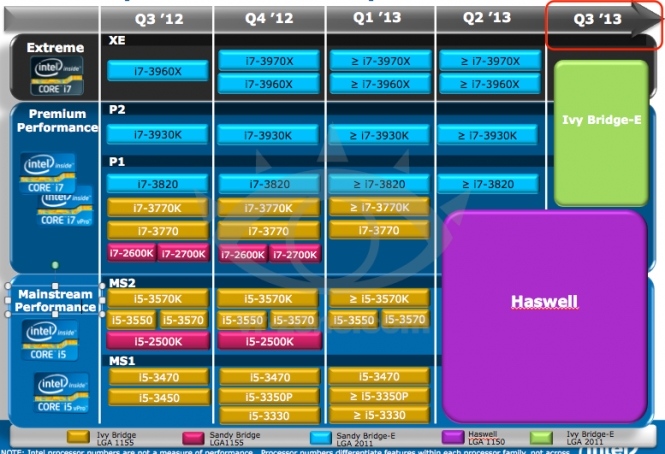
Ранее задержка выпуска микропроцессоров на архитектуре Ivy Bridge вызвала значительные сдвиги в технологических планах компании. Процессоры Ivy Bridge-E в нынешнем году уже не появятся точно, ожидать их стоит в лучшем случае в третьем квартале будущего года. Конкуренции в сфере столь высокопроизводительных процессоров Intel не испытывает уже давно, так что торопиться ей явно некуда.
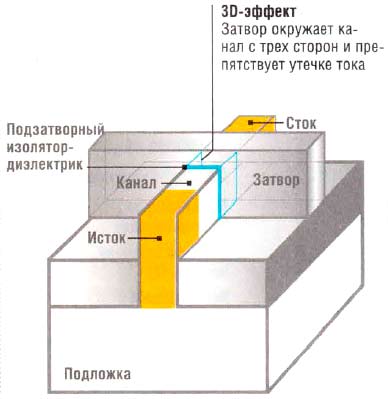
Следующим «тиком» стал обещанный переход на новый техпроцесс 22 нм в 2012 году. Однако и здесь не обошлось без революций. Усовершенствованная архитектура «мостов» выполненная по новому техпроцессу получила название Ivy Bridge. В мае 2011 года компания Intel объявила о революционном прорыве в эволюции транзисторов — использовании трехмерной структуры, до настоящего момента в массовой электронике использовалась исключительно планарная структура транзисторов. Трехмерные или 3D транзисторы Tri-Gate – это обновленная версия транзистора, где на смену традиционному плоскому слоя затвора пришла тонкая кремниевая пластина, устанавливая перпендикулярно кремниевой подложке.
Прохождение тока контролируют затворы, расположенные на гранях пластины: по два с каждой стороны и один сверху. В плоской версии транзистора использовался только один затвор, расположенные сверху (затвор является полупроводником). Использование дополнительных затворов позволяет обеспечить максимальную величину потока тока во включенном состоянии, а в выключенном – максимально приблизить к нулю за счет увеличения площади поверхности затвора и одновременного уменьшения его толщины. В результате чего сокращается потребление энергии и ускоряется их переключение. Как приятных побочный результат, такой затвор занимает меньше места, что позволяет создать микросхемы большой плотностью транзисторов. Сам Гордон Мур признает, что именно благодаря использованию трехмерной структуры транзистора, его закон продолжает действовать.
Сам трехмерный транзистор выглядит следующим образом:
Согласно оценкам компании производительность 22-нм Tri-Gate транзисторов на 37 % выше производительности планарных 32-нм структур. При этом энергопотребление у них до 50 % меньше. Однако, по последним сведениям, у этих процессоров проблемы с разгоном. При этом всем, новые процессоры стали самыми маленькими по площади 4-ядерными x86-процессорами со встроенным графическим ядром:
| Процессор | Техпроцесс | Количество ядер | Кеш L3 | Число транзисторов | Площадь ядра |
|---|---|---|---|---|---|
| AMD Bulldozer | 32 нм | 8 | 8 Мбайт | 1,2 млрд | 315 кв. мм |
| AMD Llano | 32 нм | 4 + GPU | Нет | 1,45 млрд | 228 кв. мм |
| Intel Ivy Bridge | 22 нм | 4 + GPU | 8 Мбайт | 1,4 млрд | 160 кв. мм |
| Intel Sandy Bridge E (6C) | 32 нм | 6 | 15 Мбайт | 2,27 млрд | 435 кв. мм |
| Intel Sandy Bridge E (4C) | 32 нм | 4 | 10 Мбайт | 1,27 млрд | 294 кв. мм |
| Intel Sandy Bridge | 32 нм | 4 + GPU | 8 Мбайт | 995 млн | 216 кв. мм |
Одно из главных отличий новых CPU — новое графическое ядро HD Graphics 4000, которое должно быть значительно производительнее. Этот GPU наконец стал поддерживать так необходимые DirectX 11 вместе с DirectCompute, Shader Model 5.0 и 16 универсальными процессорами вместо 12 как у HD 3000, без которых его нельзя было назвать современным. Оно также поддерживает HDMI 1.4a, что обеспечивает поддержку 3 мониторов. Опять же, новое граф. ядро, в первую очередь, позиционируется для мобильного сегмента рынка, чтобы обеспечивать более-менее конкурентную производительность графической подсистемы без внешней видеокарты.
Что радует, это совместимость новой платформы с уже существующим разъемом LGA1155 и существующим семейством чипсетов 6-й серии, например P67 (потребуется только обновление BIOS). Также, очень неожиданная новость — это поддержка нового стандарта памяти DDR3L с пониженным напряжением для ультра-мобильных компьютеров, где теперь могут отключаться линии памяти в режиме более глубокого сна.
Для пользователей же настольного сегмента, кроме более холодных систем от Ivy Bridge ожидать особо нечего: разница в производительности по сравнению с Sandy Bridge не более 3-5 %. Правда, приятной новостью станет то, что появилась возможность оверклокинга памяти с шагом 200 и 266 МГц до частоты 2800 МГц. Также, для пользователей видеокарт бонусом станет обновление PCI Express до версии 3.0, что означает увеличение пропускной способности шины до 8 GT/s, то есть почти в два раза (по тестам это около 12 Гбайт/с). Увеличившаяся на 1 такт до 24 тактов латентность кэша L3 также практически не заметна.
Осталось только добавить, что эта платформа в купе получила наименование Maho Bay/Chief River.
То, что топовые процессоры Intel сейчас вне конкуренции, очевидно всем. Это сказалось и общем замедлении темпов во внедрении новых ядер. Ко всему прочему, компания решила начать экономить, увлеклась «контролируемым» оверклокингом своих же ядер через технологию Intel Turbo, подкинула пользователям возможности оверклокинга памяти. Ну и непосредственно со стабильностью её же разогнанных чипов до частоты примерно 4,8 ГГц возникли вопросы. Все это вылилось в то, что очередной «так» компании — платформа Ivy Bridge-E — отложена до третьего квартала 2013 года.
Согласно слайду, выпуск процессоров Ivy Bridge-E Core i7 произойдёт после выхода платформы Haswell на сокете LGA1150 (Socket H3), который запланирован на второй квартал 2013 года. Ещё одним интересным фактом является то, что новый чип будет полностью совместим с существующим сокетом LGA2011 и материнскими платами на базе чипсета Intel X79 Express.
Будущий процессор Ivy Bridge-E является расширенной версией современного чипа Ivy Bridge, и будет построен на таком же 22-нм техпроцессе, но при этом будет содержать больше вычислительных ядер, каналов памяти, кэш-памяти. Вполне возможно, что Intel захочет выпустить под новый процессор и новый чипсет, но может и внести некоторые корректировки в существующий модельный ряд системной логики. К примеру, компания обеспечивала поддержку чипсета X58 Express в течение двух поколений Core i (45-нм Core i7 Bloomfield и 32-нм Core i7 Westmere).
Вернемся к ближайшему будущему — ядру Haswell, которая потребует смены платформы в связи с использованием нового сокета. Связано это с тем, что наиболее значимые изменения, влияющие на компоновочную схему будущей платформы, связаны с повышением пропускной способностью системной шины, изменением в распиновке, отвечающей для работу с шиной PCIe (включая пины FDI), изменением в схеме пинов питания и пинов для прочих целей. В этот раз было решено отказаться от использования отдельного блока с функцией питания графического контроллера процессора.
Поколение Haswell принесёт с собой ряд новых функций, в числе которых – технология RapidStart следующего поколения, позволяющая сократить время выхода системы из режима ожидания до 2 секунд. Новая архитектура позволит выполнять большее количество инструкций за такт (instructions per clock, IPC) по сравнению с предшественником в лице Ivy Bridge. В новом чипе будет полностью выполнен редизайн кэша. Мобильная версия процессора будет поддерживать функции, позволяющие ещё больше продлить время автономной работы ноутбуков основного сегмента. Ожидается снижение энергопотребления до 30% по сравнению с Sandy Bridge.
Помимо этого, CPU Haswell предлагают улучшенные возможности по перекодированию HD-видео. Предусмотрена поддержка и ряда других технологий, в том числе интерфейса Thunderbolt со скоростью передачи данных до 10 Гбит/сек и беспроводного механизма передачи данных NFC (near-field communication). Новые графические ядра пока имеются GT1, GT2 и GT3. Первые два с меньшей производительностью, нацелены на настольные решения, а GT3 на мобильные.
Сама платформа, получившая название «Shark Bay«, будет доступна в двух вариантах: двухчиповая конфигурация (4- и 2-ядерный CPU + южный мост) и одночиповая конфигурация (2-ядерный CPU, без отдельного чипа PCH). Для 4-ядерных и некоторых 2-ядерных моделей потребуются материнские платы с обычным размещением сокета на базе чипсета в составе одной микросхемы, представляющей собой чип южного моста (Platform Controller Hub, PCH), имеющей меньшие размеры по сравнению с размерами современных PCH. В то же время некоторые 2-ядерные CPU Haswell полностью «поглотят» южный мост, избавляя от необходимости использования чипсета в системных платах. Двухъядерные Haswell будут выпускаться в корпусировке BGA для пайки на плату.
Вся эта сумятица, которая ломает привычные принципы строения плат связана с тем, что компания решила поделить сегменты процессорного рынка иначе, чем мы привыкли. Обусловлено это тем, что мобильные версии процессоров уже очень приблизились по своим характеристикам к настольным, а вот версии для ультрабуков значительно дистанцировались от них.
Анализируя все это, невольно приходишь к выводу, что пришла пора смены концепций и традиционного восприятия настольных и мобильных процессоров. А вместе с этим и меняются принципы проектирования материнских плат, чипсетов. Те функции, которые много лет привычно возлагались на северный и южный мост постепенно поглощаются самим процессоров. Логично, что к этому пришли — бутылочным горлышком всех систем всегда были интерфейсы. Создавая «системы на кристалле» это вопрос снимается сам собой.
О линейном росте производительности мы забыли давно. Настала пора новых технологий, оптимизаций, наборов команд, и все это на фоне борьбы за энергопотребление с привычными системами охлаждения у потолстевших от транзисторов кристаллов. «Попугаями» уже мало кого удивишь, а бороться за рынок надо. Получается, что кремниевые гигатны отламывают кусок от хлеба вендоров плат, вбирая все в свои чипы.
В предыдущей статье мы рассмотрели, какие встречаются схемы питания в компьютерной технике в целом, а…
В статье рассмотрим, какие бывают схемы питания в материнских платах различных устройств: компьютеров, ноутбуков, планшетов,…
Сегодня в ремонте у нас программируемый терморегулятор теплого пола AC603H c Wi-Fi. Интересно, что одновременно…
Сегодня я успешно сдал экзамены и получил официальный сертификат преподавателя по операционной системе РЕД ОС,…
Мы знаем, что многие привыкли к IPTV сервисам edem.tv, iedem.tv, itook.tv и их зеркалам. Ведь…
Geekbench - пакетов тестов для измерения производительности хостов. Он доступен в разных версиях - 4,…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}